

The Case for Liquid Training

Thesis
Compute is the limiting reagent of modern intelligence.
Our thesis is that the next decade of AI economics is the story of refining it — and that the single most valuable product of that refinement is liquid training: training as the always-on baseload that lets every GPU in the world capture inference peaks.
We must disrupt the fundamental economics of training.
iota turns idle, stranded compute into liquid training capacity for the global AI economy.
We are building the load-balancer that turns existing peak-driven clusters into training capacity at near-zero marginal cost, democratising the training of frontier scale models across the globe.
iota is built to enable this future.
Efficiency is king
Today, much of the AI industry buys compute the way the early-20th-century chemical industry bought crude oil: in bulk, undifferentiated, from a handful of integrated producers. That paradigm worked when the only consumer was a single, monolithic refinery. It does not scale to the dozens of distinct training, inference, and fine-tuning workloads now competing for the same finite GPU pool.
In conditions of abundance, relative position becomes the scarce asset. In a compute-constrained market, the inversion holds: when everyone is buying the same chips, the scarce position is efficiency — the productive GPU-hour.
Building more capacity is necessary, but making installed capacity more efficient is king. Hyperscalers and Frontier Labs spend billions of dollars tackling this problem - solutions like GKE (Google Kubernetes Engine), spot-pricing on AWS and OpenAI’s Batch API’s are all solutions to the challenge of maximising effective GPU hours in a way that also responds to peaks.
The last decade was about optimising peak performance for clusters; as demand scales exponentially in the next, the challenge will shift to total economic throughput per installed watt.
Where value is created
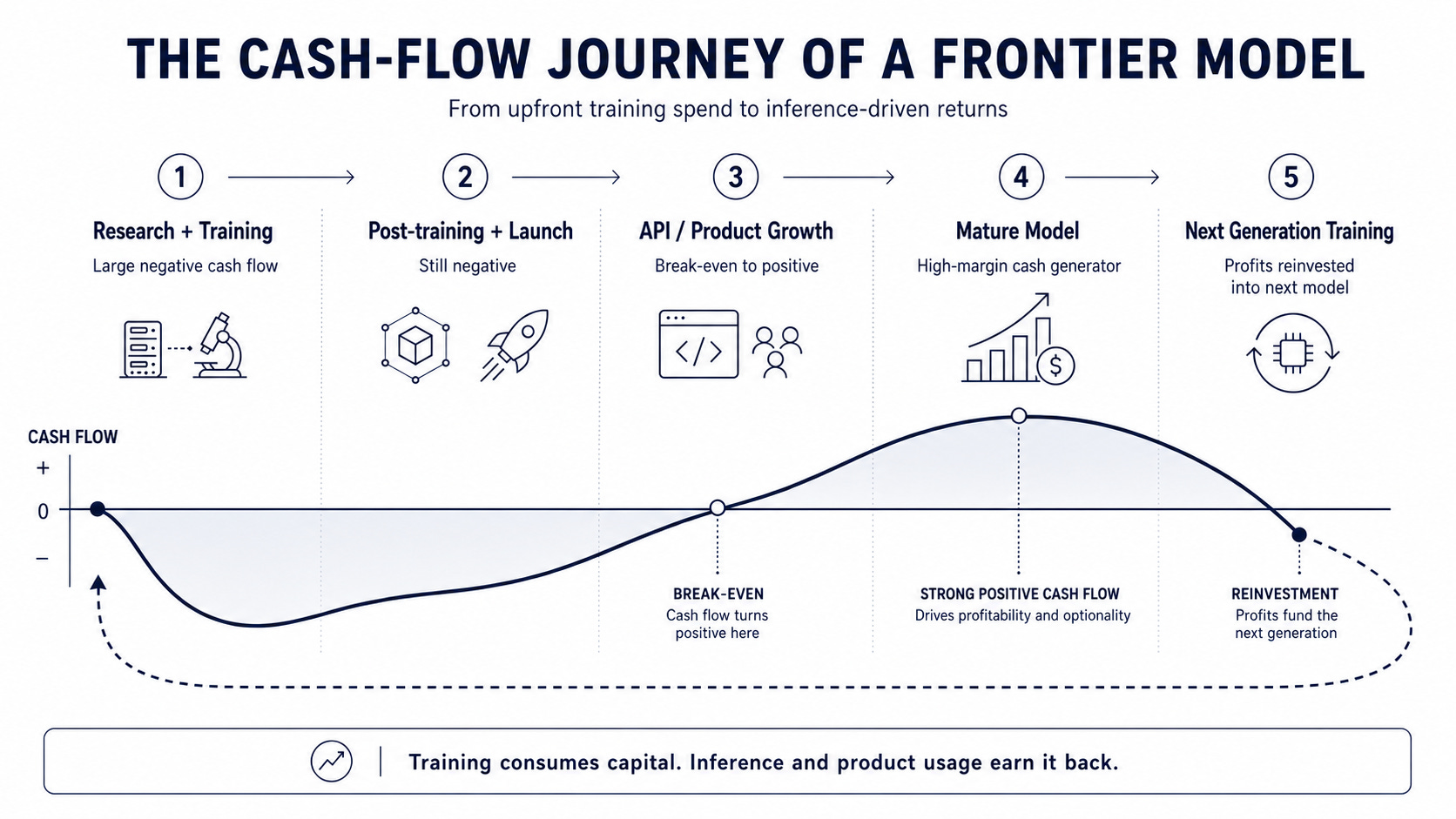
Training consumes the capital. Inference earns it back.
AI workloads split into two core activities.
For model builders and AI applications, training is the upfront capital commitment: research, pre-training, post-training, evaluation, and launch before the model has fully proven its commercial return.
Inference is where that investment is realised — at the point of token utilisation by a user, API customer, agent, or application. It is where the model moves from capital expenditure into product usage, revenue, and margin.
That distinction matters. The training phase is long-running, fragile, and colocated. The inference phase is demand-sensitive, latency-sensitive, and provisioned around uncertainty: capacity must be available when users, agents, and applications call for it, even when demand is uneven across time, geography, and workload type.
Training is critical to the boom; without it there are no better tokens to sell. But in its current form, large-scale training can consume committed capacity for long periods of time — exactly the kind of capacity the market increasingly needs to flex across inference, fine-tuning, evaluation, and future workloads.
Many of these problems are functions of time; how to optimize utilisation over a 24 hour period.How to exist in a world where the useful competitive life of a model is 3 months, and how to dealwith a compute build-out that is already in chronic delay, that is only likely to get worse.
The strategic goal of the compute industry is to maximise total useful compute available at any given time step. Today’s training paradigm works directly against it.
Liquid training
The unlock is making training liquid: interruptible, heterogeneity-tolerant, bandwidth-tolerant work that fills the gaps rather than forming the bedrock.
The economics are straightforward.
For any GPU owner, incremental utilisation above baseline cost recovery is direct margin return. As an illustrative fixed-cost scenario, moving a fleet from 60% to 85% productive utilisation spreads the same installed cost over more useful GPU-hours, lowering the effective fixed cost per productive GPU-hour by roughly 30%.
The realised economics will depend on workload mix, headroom, power, orchestration, networking, and commercial pricing, but the direction is simple: more value from the same installed base.
A liquid training workload arbitrages those troughs, drives overall utilisation towards 100%, and lets owners flex capacity to inference at peak without disrupting synchronous workloads.
Three properties are non-negotiable:

The first proof points are now visible.
Our work on iota, and the published results from Orion-100B, show this is no longer hypothetical: 100B-parameter models trained within 65% of centralised paradigms, at 30% of the cost by using heterogeneous, non-frontier, available hardware. You can read more about Orion in our article Distributed pre-training arrives.
We have taken this from an impossibility to a reality in eighteen months.
Conclusion
We are in a compute-constrained market, mid-way through the largest capital expenditure in the history of humankind. The question that decides who wins is not who installs the most capacity, but who extracts the most intelligence per installed watt.
Liquid training is how.
It turns the most rigid workload in the stack into the grid’s backfill load, lets GPU owners capture more value from inference peaks, and squeezes every single drop from the lemon.
Greater output from installed capacity. Better unit economics for suppliers. More total effective flops for AI.
This future is finally within our grasp.
We are taking iota to market with pilot customers in the latter half of 2026.
This is the first instalment of our commercial thesis for iota. In the next pieces, we will go deeper on the economics of utilisation, the technical requirements for liquid training, and the proof points that make this market-ready.
If these ideas resonate, get in touch: hello@macrocosmos.ai.
Sign up to our newsletter to receive the rest of the series.
Explore further
Distributed pre-training arrives → Orion-100B and our results
Welcome to Train at Home → how to participate in distributed training
Meet Alan → AI Research Lead at Macrocosmos
See IOTA in action → IOTA dashboard
Learn about the Macrocosmos ecosystem → macrocosmos.ai