Orion-100B: Distributed pretraining arrives at hundred-billion-parameter scale
Author: Dr. Steffen Cruz

Abstract
We present Orion-100B: to our knowledge, the largest distributed LLM pretraining run conducted over the open internet across globally distributed infrastructure. Orion-100B is an early pretraining run training a 100B parameter model across 16 pipeline-parallel stages, using globally distributed single GPUs, achieving upwards of 30% model FLOP utilization (MFU) on Nvidia A100-80GB chips during training. With this, IOTA becomes the world’s first technology that can feasibly train hundred billion parameter-scale models across the internet under economically advantageous conditions.
Orion-100B achieved roughly 65% of the training speed of equivalent datacenter setups while using distributed hardware that costs a fraction as much. We believe that this work presents, for the first time, an economically compelling case for training large models using distributed approaches.
Summary
IOTA is a distributed pipeline-parallel training architecture developed on Bittensor Subnet 9 around a simple thesis: that frontier-scale foundation model training over the open internet could be made not merely technically feasible, but economically superior. If successful, this would allow model training to scale beyond the economic and operational limits of today’s frontier datacenter-centric approaches. Today, there are clear signs the thesis may be correct.
The present was possible due to several key innovations that were developed over a year of work in IOTA:
The creation and utilization of ResBM, currently the state-of-the-art (SOTA) technique for lossless activation compression in LLM training,
A custom, fault-tolerant peer-to-peer networking protocol that optimizes throughput & latency across heterogeneous GPU nodes,
Reliable distributed variable synchronization (a.k.a. IOTA Bridge Service).
These advancements have enabled IOTA to increase training speeds by an order of magnitude since its inception, and support training across many pipeline stages without significant costs to net throughput.
The results presented in this report set the foundation for further work. Project Orion will continue by progressively relaxing the assumptions of the training environment. We intend to demonstrate that heterogeneous hardware, interruptible compute, permissionless participation, and eventually consumer-class peers can contribute not only economic advantages, but also the creation of genuinely open and democratic AI infrastructure.
Preface
I recall a salient moment last October at open source AI week in San Francisco, where Will and I were invited to speak at an event at Frontier tower. The evening was structured as a friendly debate on the feasibility of decentralized training, and we were to represent the bull case. Across from us, a leading researcher gave his view; the bear case. Pretraining models in a distributed fashion is, to use his words “like fighting gravity”. He left shortly after delivering his speech. There was a finality to his view that made us uneasy, and we stayed up late into the night discussing whether we were in fact delusional by even attempting to make IOTA work. Such an irreverent dismissal from someone of this standing is not something I will easily forget, but the truth is this is a broadly shared opinion towards decentralized training. When IOTA launched in June 2025, the prevailing view in the field was that pipeline-parallel distributed training over commodity internet was either impossible or so inefficient as to be irrelevant.
Most decentralized-training efforts to date — INTELLECT-1, Psyche Consilience, Covenant-72B — have all chosen the distributed data-parallel route (DDP): every peer hosts the full model, and the optimization is wrapped in communication-efficient outer-step machinery (DiLoCo, SparseLoCo) that compresses the parameter-axis communication into something the open internet can carry.
That path works. Covenant-72B demonstrated it at an impressive scale. But it has a structural limit: the largest model you can train is bounded by the memory of the smallest peer you’re willing to require:
Covenant peers must run 8×B200 GPUs at a cost of approximately $50 per hour per peer. That is “permissionless” in the protocol sense but emphatically not in the participation sense — almost no one can join. Importantly, DDP is fundamentally about speeding up training, not enabling otherwise inaccessible training. In principle, a single node could just train the model without the networking overhead. The benefit to DDP is an approximately proportional speedup with the addition of more compute nodes, and even this reaches diminishing returns beyond a couple dozen nodes. When the nodes themselves are datacenter-sized, this might make sense (eg. Google DeepMind), but for practical purposes there does not seem to be a viable path to train a decentralized frontier model in this fashion.
IOTA chose a different route: split the model itself across peers, using distributed pipeline parallelism (DPP) over the open internet. Each peer hosts a fraction of the model — as little as a single transformer block — and contributes a single commodity GPU (or Apple Silicon device). This dramatically lowers the barrier to entry for decentralized training: instead of requiring every participant to host an entire model replica, the network can onboard compute incrementally, one GPU at a time. More importantly, pipeline parallelism allows the network to aggregate that distributed hardware into a single larger system. As additional peers join, total model capacity scales with the aggregate memory and compute of the network rather than the limits of any individual machine:
In that sense, DPP is fundamentally aligned with the spirit of decentralized systems: many small independent contributors combining into something no single participant could achieve alone. These observations give me hope that one day we may be able to train the largest models in the world in a truly decentralized manner.
Of course there is no such thing as a free lunch: IOTA exchanges the hard ceiling of DDP for an even harder technical problem of solving DPP, but raises network capacity by orders of magnitude in turn (more on this in an upcoming article). Rather than relying on mostly independent training nodes, as is the case in DDP, the system becomes irreducibly entangled when the model itself is distributed. The upfront technical lift is enormous in comparison.
A single training step in IOTA requires incredible amounts of data transfer, and reducing this as much as possible is a key component in making DPP possible. Therefore, we needed to go beyond the previous methods in activation compression to prevent crippling data transfer overheads, leading us to publishing ResBM, our state-of-the-art method for lossless activation compression. We had to build a new peer-to-peer distributed training system from the ground up to ensure fault-tolerant training communication at scale. We did both, in under a year.
We iterated endlessly on our approach; rewriting our codebase multiple times and training over 750 small models across a wide array of compute and model configurations. One of the benefits of DPP is that many of the technical challenges that are present when training very large models can be solved by iterating on small models; a model sharded around the globe is a model sharded around the globe after all.
The Year-one Journey
Bittensor has proven to be an exceptional environment in which to develop this system. Its scale, network dynamics, adversarial permissionless setting, and highly capable community have helped harden the architecture and stress-test these assumptions under real operating conditions.
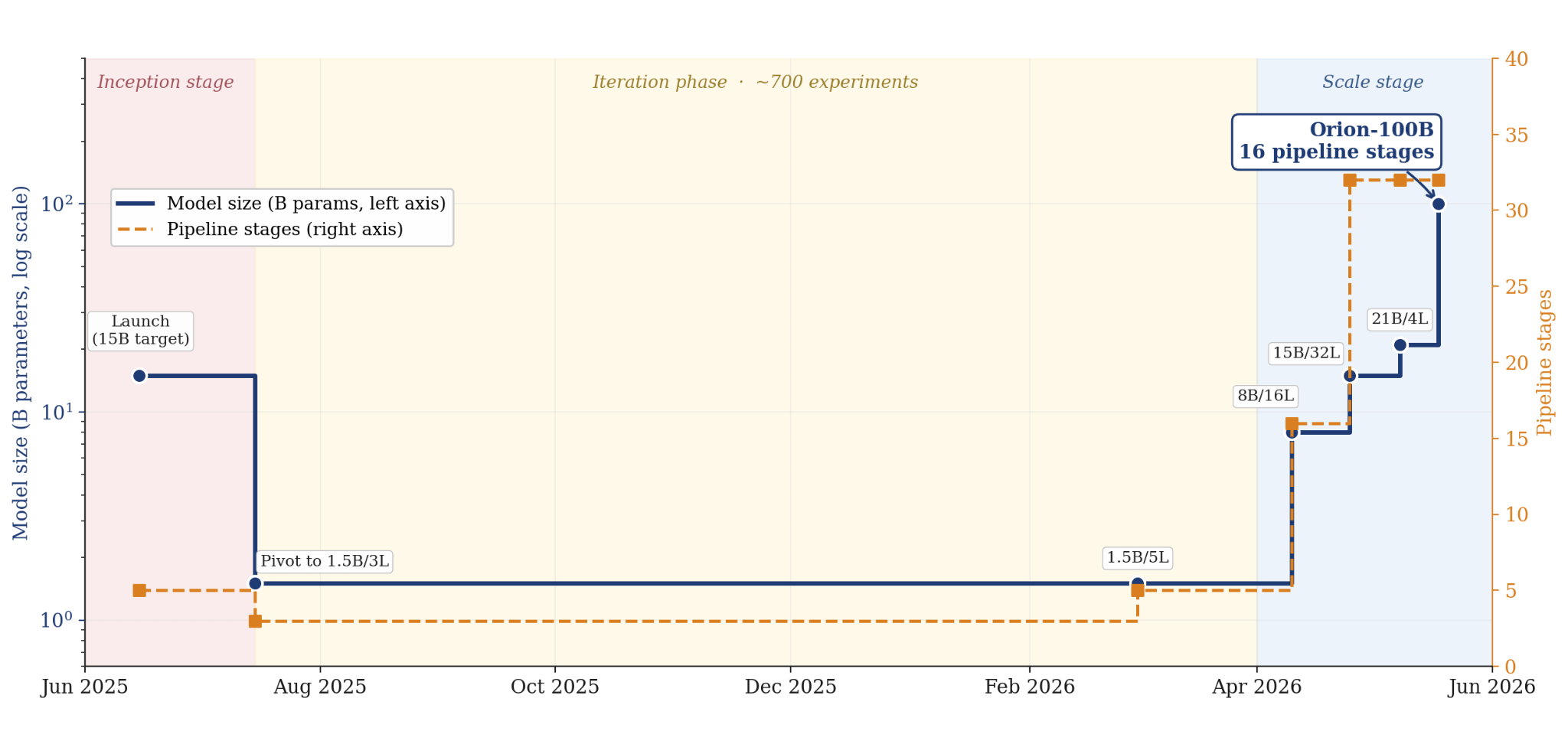
Our work on IOTA began in April 2025. Driven by encouraging internal results we launched in early June 2025 with a permissionless 15-billion-parameter target model, split across 5 pipeline stages. The system fell over almost immediately due to a combination of system overload and adversarial attacks. The upfront complexity was overwhelming.
In July 2025, we made the decision to reduce the scale and increase iteration speed. We picked a 1.5B-parameter / 3-layer test-bed configuration; small enough to train quickly but complex enough to learn the important lessons from. This was unglamorous, unpopular and, in hindsight, the most important decision we made.
Between August 2025 and April 2026, we ran over 700 controlled experiments on our 1.5B/3L testbed. In total, we trained for almost 15 trillion tokens during this period. We rebuilt every part of our codebase and entire infrastructure stack to be more performant and scalable, introduced better communication primitives and benchmarked machine learning efficiency against our own centralized baselines. The goal at this point was to de-risk the system, not to train a useful model. Over the course of this period, the system throughput increased by roughly an order of magnitude, which was a prerequisite for the work we present in this report. On the contrary, training a 100B model was almost certainly possible 6 months ago, but starting later and training faster was the correct decision as we would have already overtaken that hypothetical run in terms of tokens trained.
By April 2026, we were confident that the system was ready to be tested on larger models. The two primary axes of scale for IOTA are model size and number of pipeline stages (or equivalently, smallest compute node), so we carefully increased both and continued benchmarking our system performance against the baseline case. With our solid foundations, we were able to scale model size by 67x and pipeline stages by 10x, in a single month.
By the time we launched Orion-100B, the system had been validated through over 750 experiments from 1.5B through to 21B parameter model scale. Equipped with this data, we knew it was possible to train models that were significantly bigger than anyone had ever tried before.
Orion-100B
Orion-100B was conducted as a 16-stage pipeline-parallel run with 3 replicas, equalling a total of 48 devices. Each stage was hosted by a non-colocated peer, which were geographically distributed across 5 datacenters within the United States. Each peer contributed a single A100 80GB GPU, provisioned from multiple providers with median upload/download speeds of 856/1322 mbps respectively.
This specific configuration was intentionally selected to balance cost with reliability, and enable us to demonstrate the strengths of the IOTA training system.

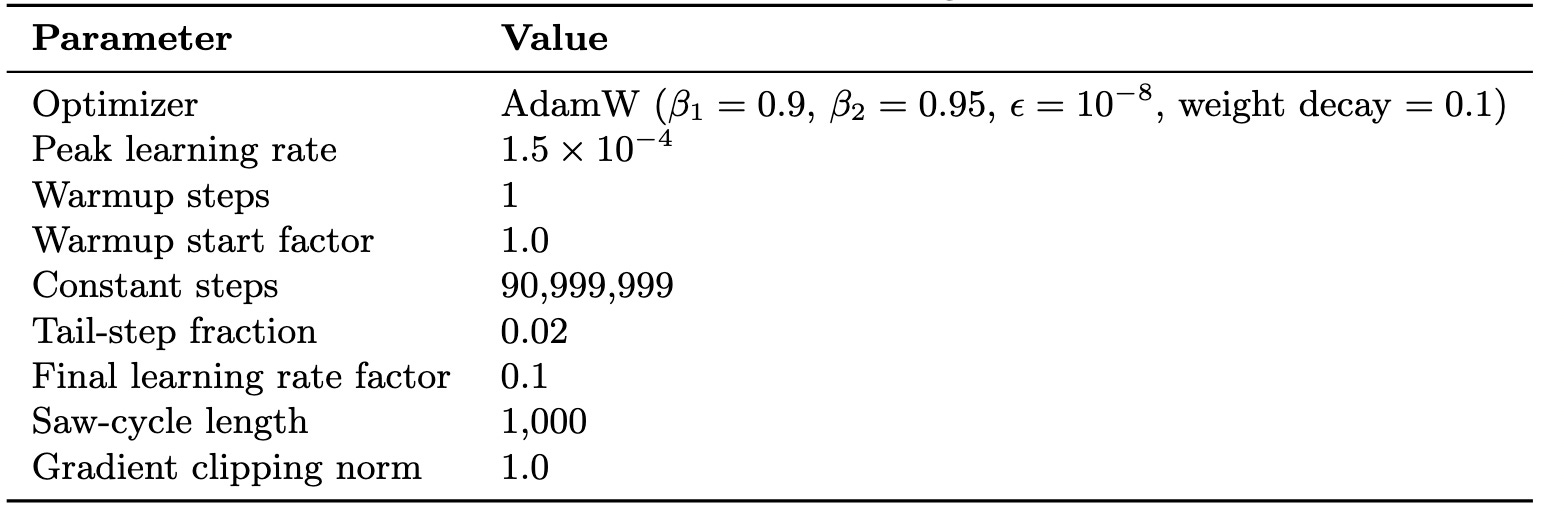
The network trained for approximately 1.1 billion tokens of the fineweb-edu-score-2 dataset, over the period of approximately 2 days before it was stopped for cost reasons. The model used was a modified llama3.2 architecture with ResBM compression at each pipeline stage, reducing the native dimension of hidden activations by 64x. Correspondingly, the size of activations that were transferred between stages was reduced from 140.6 MB to 2.2 MB. Further details about the model and training config are provided in Appendix A.
In IOTA, the network cycles between three phases: training, weights uploading and weights merging.
During the training phase, we used a stochastic pathfinding algorithm for peer-to-peer activation routing, co-developed by our IOTA team and miners in Bittensor Subnet 1 (via our Apex competition platform), to maintain fault tolerance while sustaining high network throughput. Our approach was inspired by earlier work on SWARM parallelism by M. Ryabinin. Importantly, computation and peer-to-peer communication occur concurrently so as to minimize time lost to communication. Each replica performed approximately 10 inner steps (H=10) before the system automatically transitioned to the synchronization phases, weights uploading and weights merging. The small number of inner steps in Orion-100B was selected to prioritize training stability over training speed in the present work, but it is already well-established that DiLoCo-based distributed training is stable up to 500 inner steps. By increasing the number of inner steps even to 100, the fixed communication overhead of synchronization is amortized further.
Weight synchronization (weights uploading and merging) in IOTA is parallelized across stages: every stage syncs its own slice of the parameters concurrently with every other stage. Because of this, synchronization occurs faster in IOTA than in DDP training systems by a factor equal to the number of pipeline stages. While we decided to use 3 replicas for cost reasons, adding additional replicas has two clear benefits to IOTA: higher training throughput and reduced synchronization time due to the mechanics of the butterfly all-reduce synchronization primitive.
Results
Orion-100B was trained to 1.1B tokens, sustaining an average training MFU of 30.8% and a peak sustained training MFU of 38% over a 6 hour period without churn, which equates to training on average ~65% (peak sustained 82%) as fast as using co-located devices with high bandwidth interconnect. The average system throughput during training was approximately 9000 tokens per second. To our knowledge, this work presents the highest MFU reported for any distributed pipeline-parallel training run.
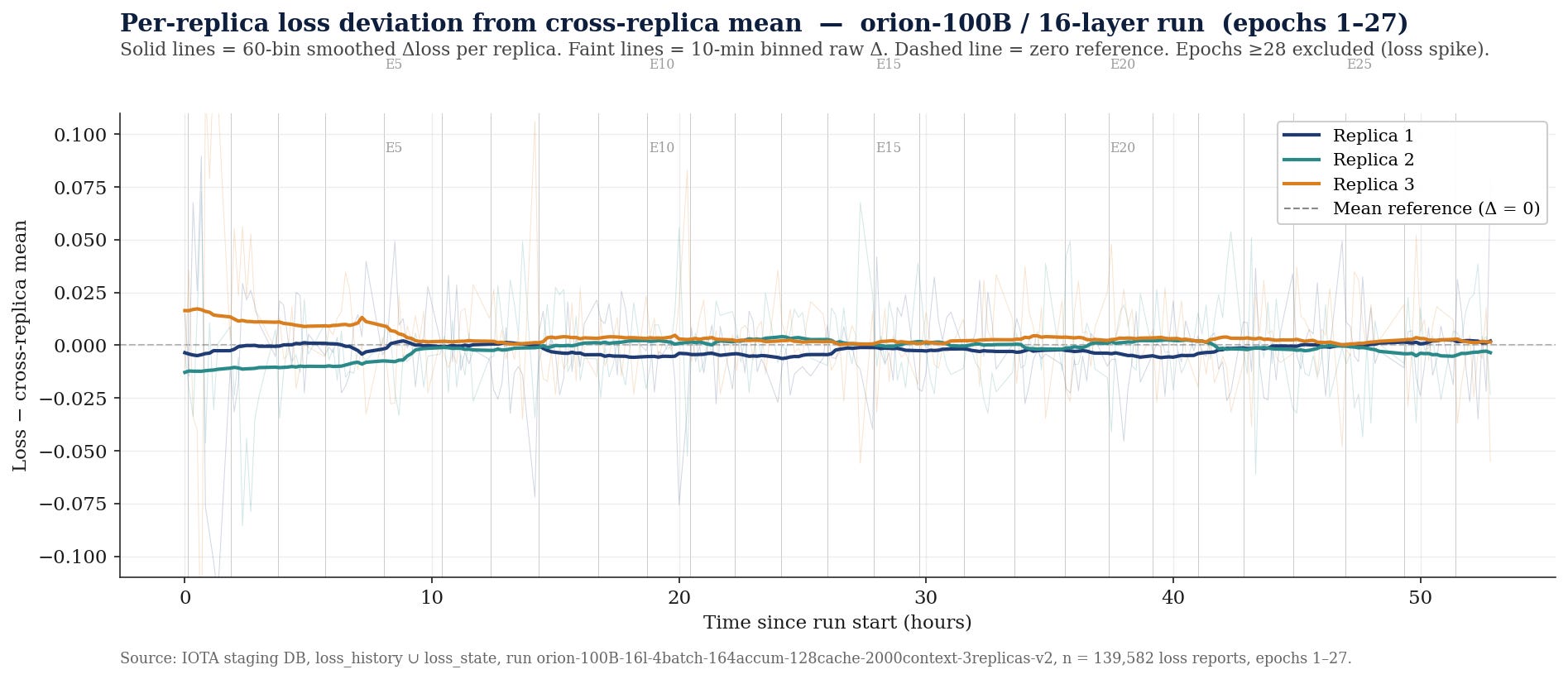
The figure below shows 28 full cycles of Orion-100B training, which demonstrates stable learning dynamics.
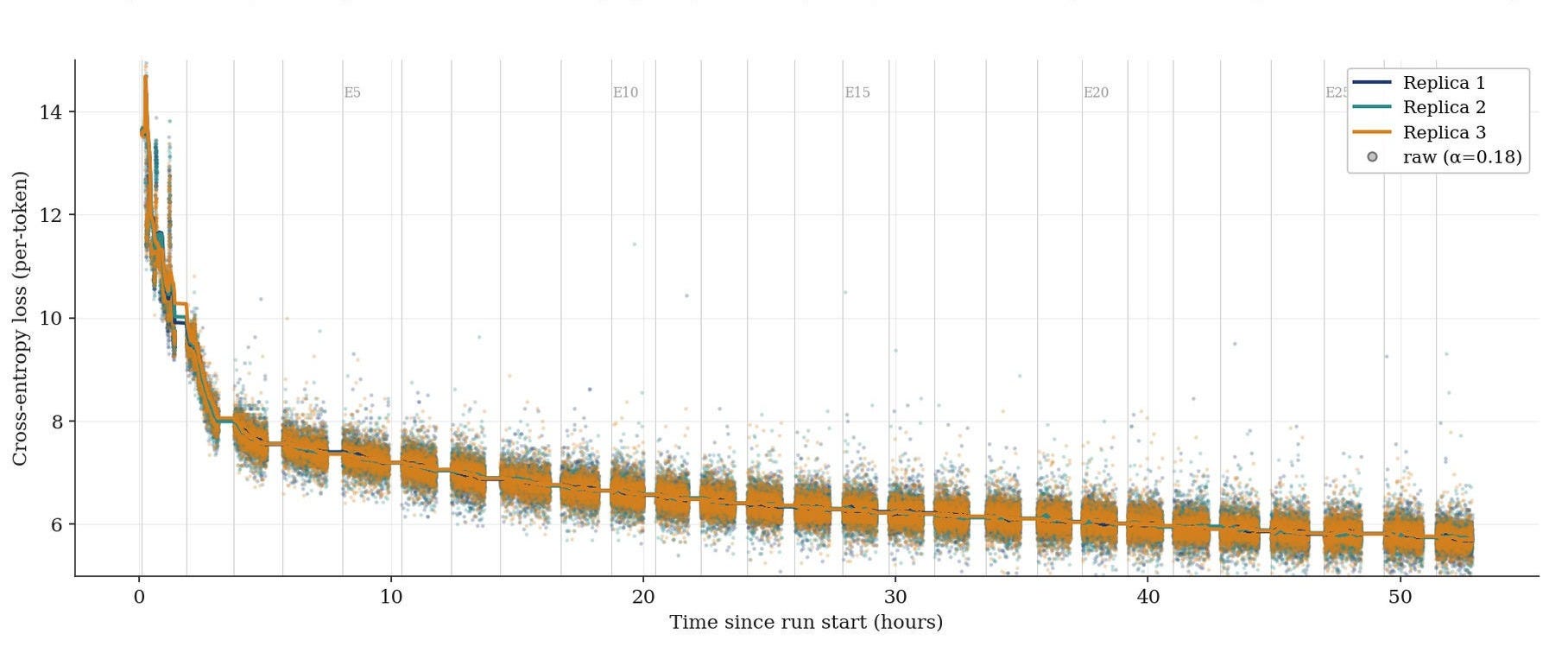
In addition, we observed excellent consistency between replicas throughout the duration of training. This result validates that our stochastic pathfinding algorithm is able to preserve a coherent global state during training despite using dynamic pathways through the model.
During the Orion-100B run, the training and synchronization phases lasted on average 100.2 and 22.2 minutes, respectively. The plot below compares the time spent by Orion-100B in various system phases to notable distributed training runs using publicly available data from Prime Intellect and Covenant AI. Orion-100B achieved overall training utilization of 81.8%, which matches INTELLECT-1 whilst training a model 10 times larger.
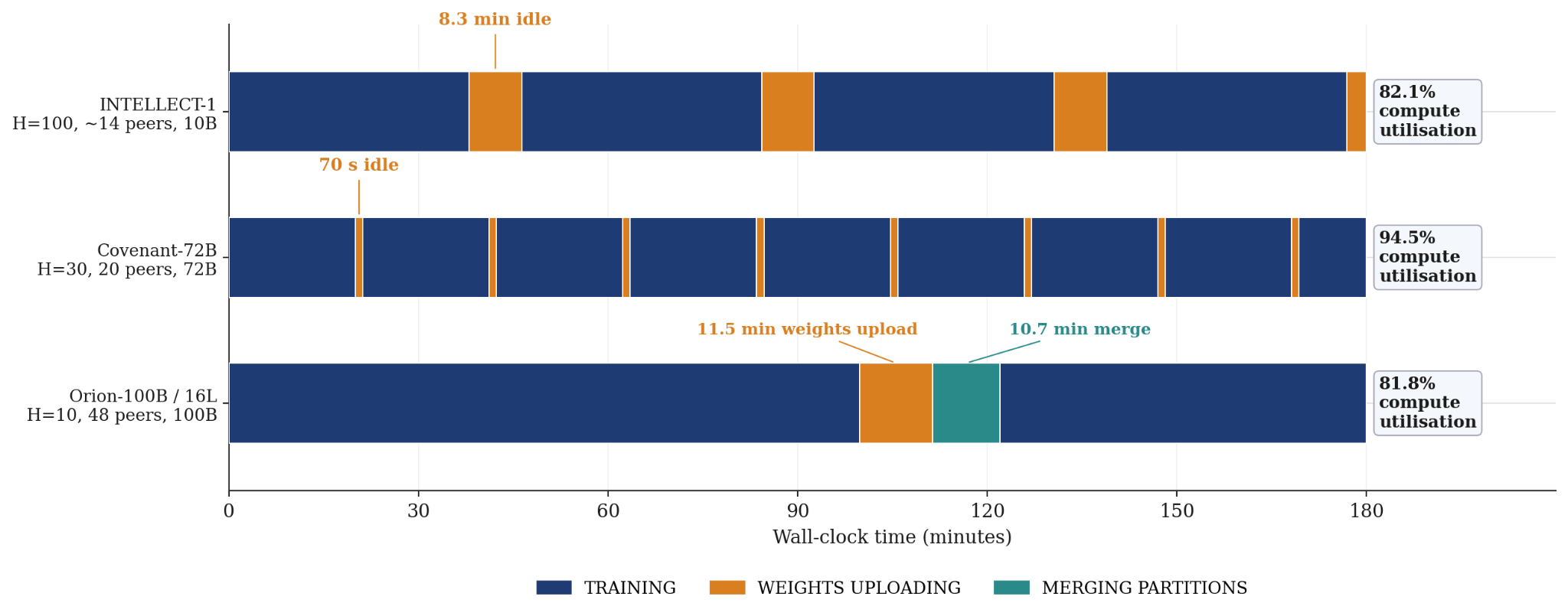
By increasing the number of inner steps by 10 times (to H=100), the overall compute utilization can be increased to 97.8% with no expected impact on model quality. Additionally, Orion-100B did not make use of any pseudogradient compression schemes such as DeMo or SparseLoCo due to unstudied interactions between ResBM and these syncing techniques. By introducing even modest compression, we anticipate synchronization time can be reduced to less than 0.5% of total training time. We leave demonstration of this to forthcoming work.
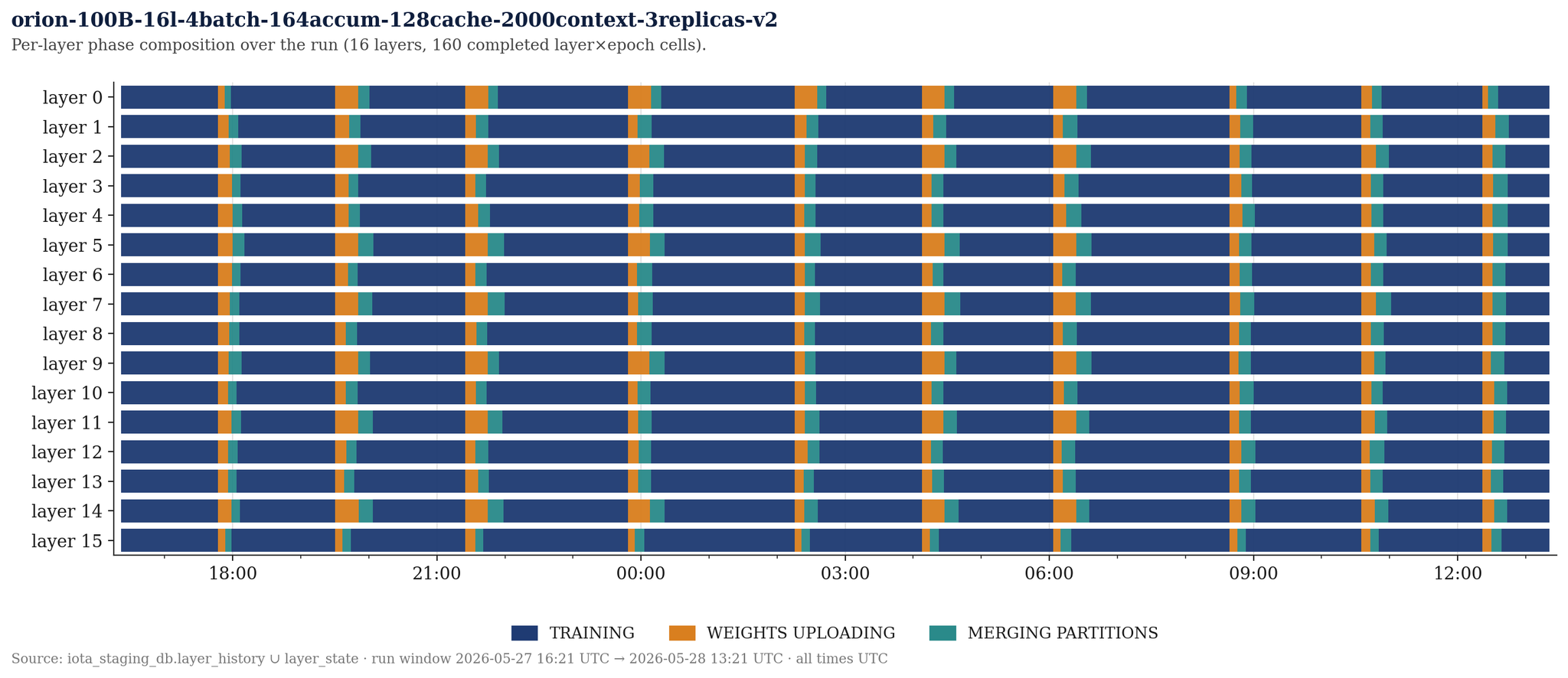
Notably, several bandwidth-limited devices occasionally took substantially longer than their peers to upload weights, as can be seen in the plot below. While this caused increased system idle time, the fault-tolerance of IOTA allowed the run to continue training unimpeded.
Perhaps the most striking property of the Orion-100B run is its cost per replica. A Covenant-class peer (8×B200) costs approximately $50 per hour at mid-2026 cloud market rates. An Orion replica (16 non-colocated A100s at $1.25 per hour) can be provisioned for as low as $20 per hour — 2.5× lower entry cost. We find it encouraging to the ethos of decentralized training that Orion-100B is constituted such that individual peers can participate for as low as $1.25 per hour.
Project Orion and Future Work
Orion-100B was conducted as a system-viability proof. The question we set out to answer was does our pipeline-parallel approach, using ResBM compression, work at hundred billion parameter scale? After approximately 750 experiments, four scaling steps, and the Orion-100B early pretraining results, we believe we are making substantial progress to proving this thesis is correct.
This work is the first step in a larger programme, which we call Project Orion. Having shown viability in the present case, in the coming months we intend to progressively relax the current restrictions to demonstrate the efficacy of IOTA as a more generalized, decentralized system. That subsequent work will deliver further proof points as we progress step by step through:
Heterogeneous - using a mixed GPU fleet. Heterogeneity will allow IOTA to train using a blend of different hardware, unlocking the long tail of older (“obsolete” in frontier terms), stranded, underutilized compute. We expect to derive substantial cost savings as owners seek to cover operating cost.
Interruptible - using interruptible spot-market GPU instances. These are available at up to 90% discounts vs. reserved hardware, in return for the provider’s ability to “reclaim” them at short notice. It is a unique advantage of IOTA’s fault tolerance that we can train on this basis.
Permissionless - allowing untrusted contributions from decentralized compute and third parties. This removes the final centralized pillar of the system and offers a path to significantly larger, internet-scale training.
Consumer - onboarding smaller, consumer-grade (e.g. 4090/ 5090/ M Series) machines to participate in training runs. Train at Home has already demonstrated that this is possible; we intend to develop the broader IOTA system to enable consumer hardware to participate in larger scale model training, deepening the pool of potential contributors.
We believe that, once complete, Project Orion will provide definitive evidence that decentralized training can be economically competitive at a meaningful scale.
FAQ
Why was Orion-100B only trained on 1.1B tokens?
This is a system viability demonstration, not a complete model training run. We consider this a sufficient demonstration of IOTA’s capabilities within acceptable cost limitations.
Why is Train at Home not training a 100B parameter model?
Train at Home is a fully functioning training swarm live on Bittensor, using the same technology as Orion. Although the system is theoretically capable of training large models, it is a demonstration where all the constraints described in the “Project Orion and Future Work” section are already relaxed and the further work described is required to support acceptable speed and machine learning outcomes.
Learn more
About IOTA: https://iota.macrocosmos.ai/
About Macrocosmos: https://www.macrocosmos.ai/
Appendix A
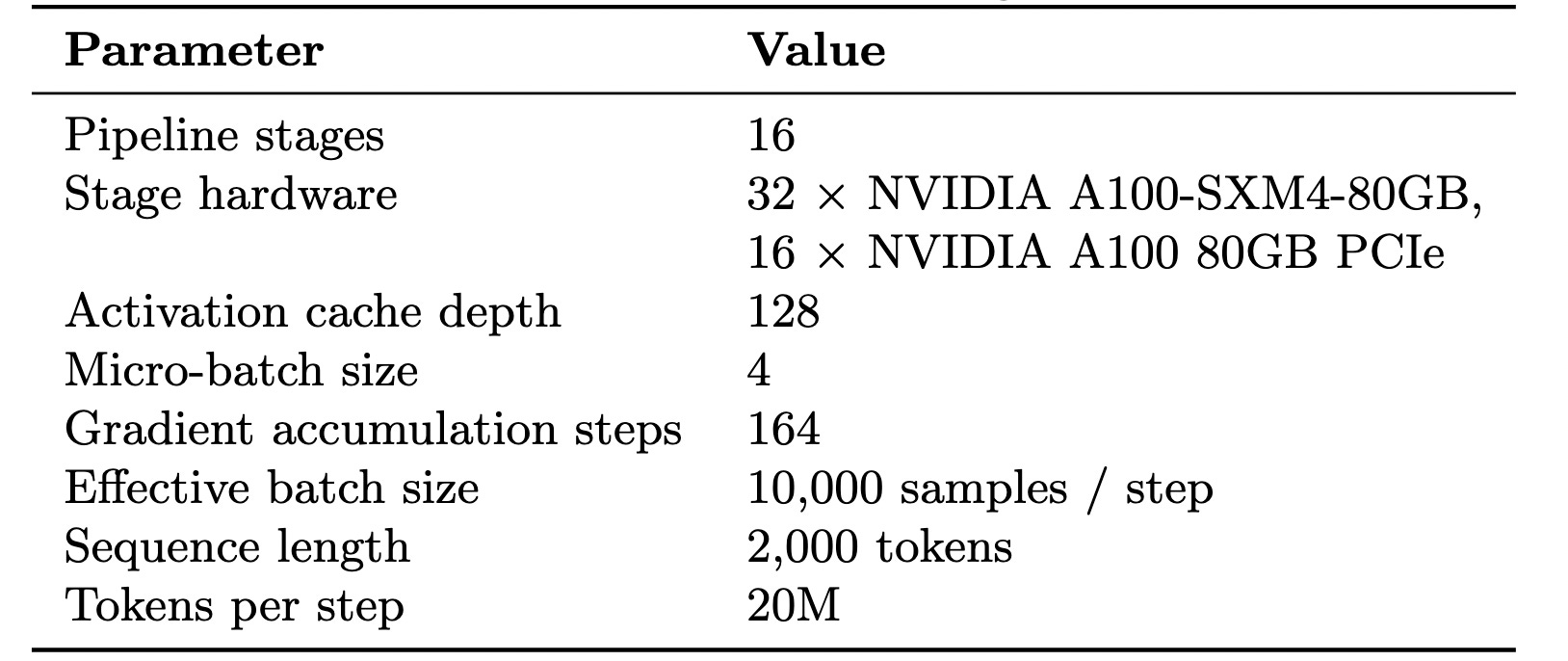
The numbers below are the operational configuration of the Orion-100B run.
A.1 Dataset

A.2 Base model architecture
Orion-100B follows the Llama-3.2 family architecture, scaled to 100 billion parameters.
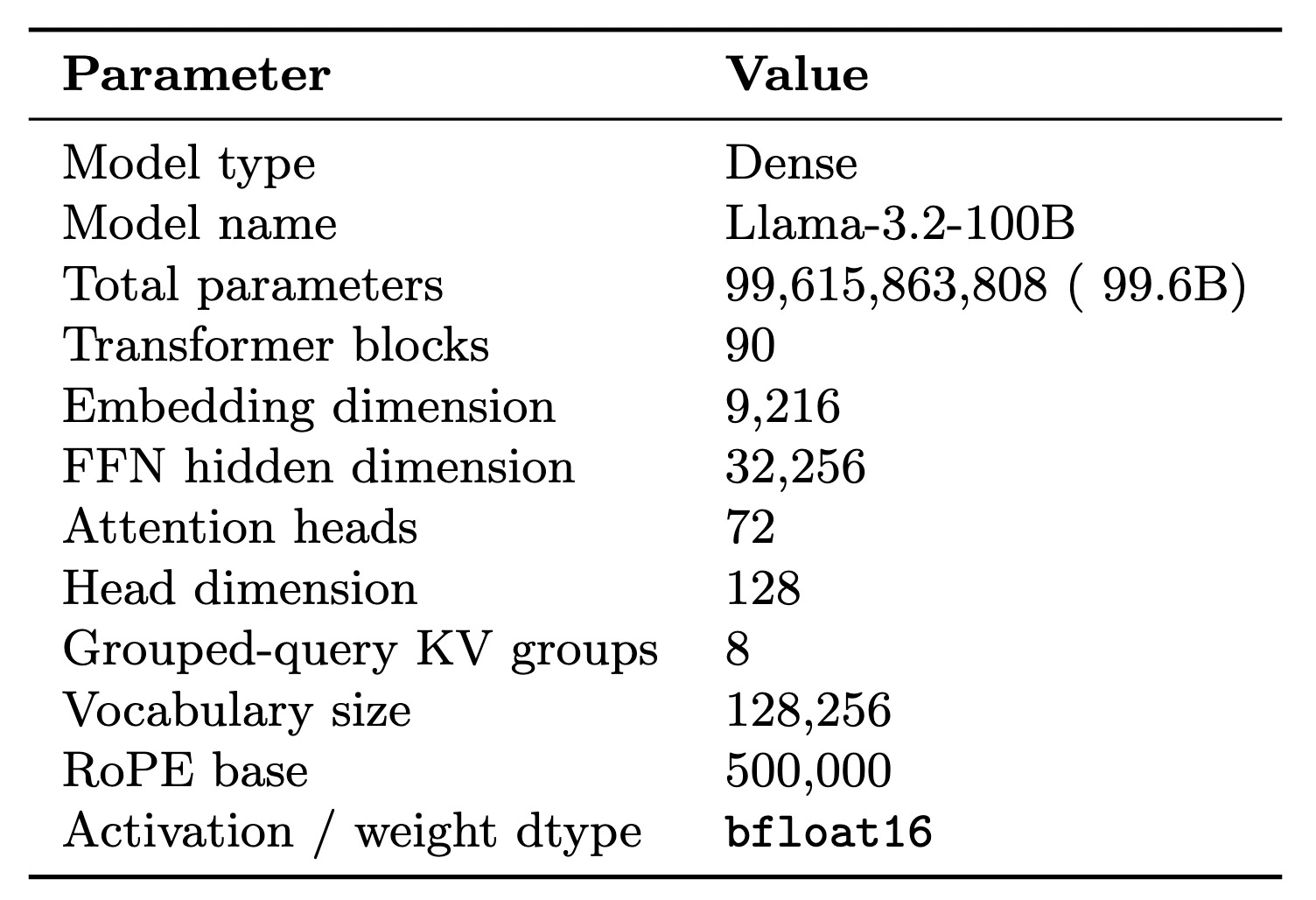
A.3 Pipeline configuration
The 90 transformer blocks are sharded across a 16-stage pipeline (n_splits = 16), with one peer per stage. The split is asymmetric: the first and last stages also carry the embedding and the LLM head respectively and so hold fewer transformer blocks than the interior stages.
A.5 Optimizer & schedule