

Why IOTA is different: Comparing Pretraining, Federated Learning, and Swarm
Subnet 9 has relaunched with a brand new decentralized pretraining setup, but what exactly sets it apart from others on Bittensor?

Subnet 9 is now the home to the world's first ever model parallel and data parallel incentivized trustless pretraining protocol - but what makes it such a significant improvement on SN9’s previous decentralized pretraining competition, and what advantages does it hold over other pretraining systems?
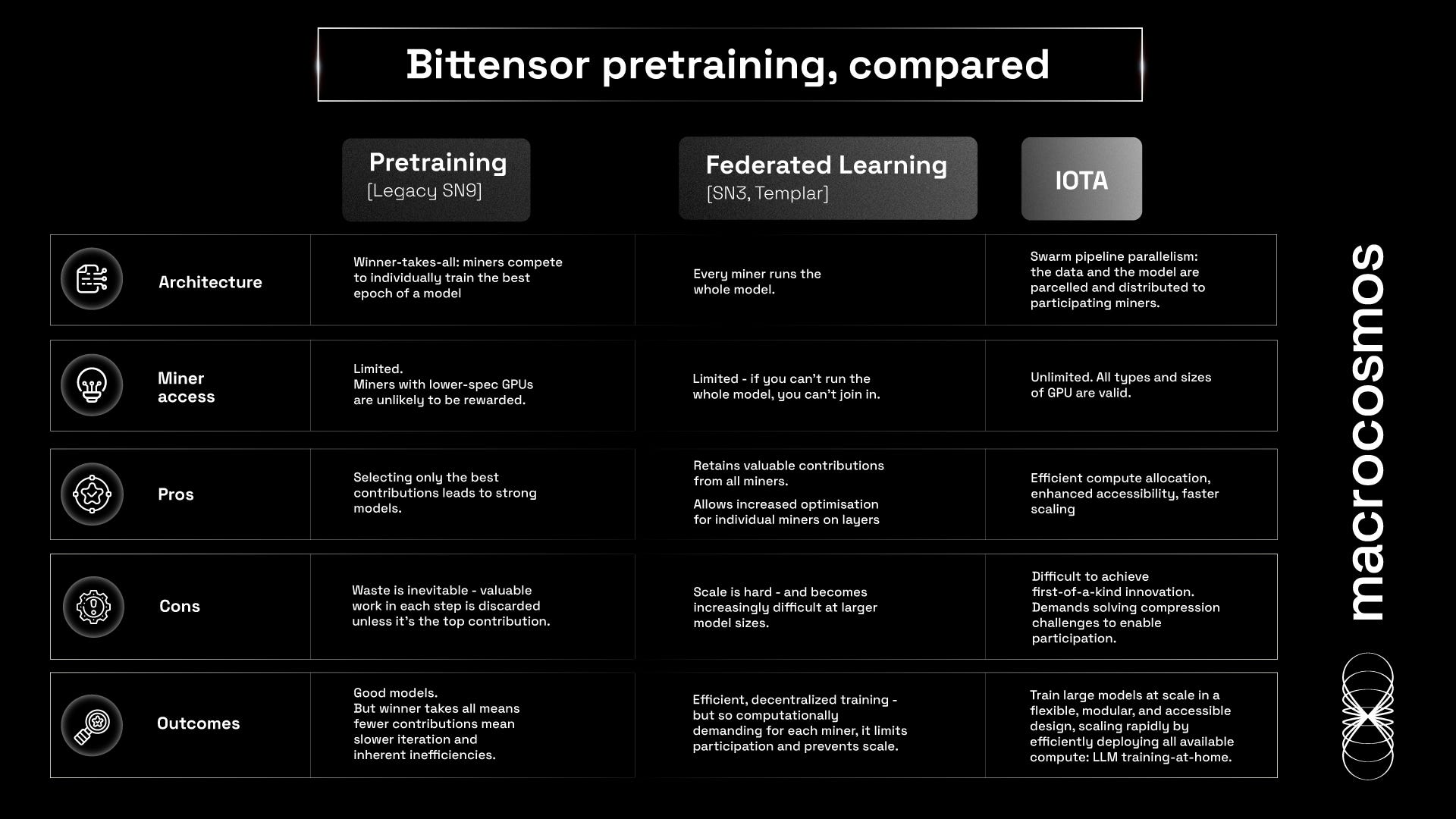
Pretraining [SN9’s legacy design]
In Subnet 9’s earlier architecture, miners would compete to individually train the best epoch of a model. In each step, only the best model is selected, rebased, and rewarded.
This winner-takes-all design creates good models. But there's inherent loss - because all work in that step that isn't in the best miner is discarded, even if it happened to include novel and useful work. But accepting only the top output is inherently inefficient, because most work is lost.
Federated Learning [SN3, Templar, and SN38, Distributed Training]
In Federated learning, the miners run the whole model via data parallelism. This means running multiple copies at once - therefore, each participant must maintain local copies of the whole model. Miners are assigned specific tasks, training the model on local data, and then sharing their updated model. These updates are merged to form a single model, with miners rewarded in proportion to their contributions to specific elements in the model.
However, because each miner must be able to fully run the whole model, the computational demands for each are significant. Which means participation is hardware-bound: the barrier to entry is limited to those who have sufficient compute. And at the frontier-model level (100bn parameter-plus), the amount of compute each miner needs is practically a data centre.
This is an obstacle to scaling federated learning. In order to do so, you’d need multiple data centre-sized miners. Not only is this prohibitively expensive, it can also become close to centralized training through large data centres.

IOTA [SN9’s data and pipeline parallelism]
With swarm learning, we have the best of all worlds. We can portion the model in each band into many pieces. This allows more versatile participation, because it facilitates contribution with a greater variety of miners with varying computing capacity - effectively expanding the total sum of the subnet’s available power.
And it also means that, in every step, the model is enriched by the valuable outputs from all participants. Unlike in SN9’s legacy winner-takes-all design, which discarded all but the very best, IOTA retains contributions of value from everybody.
Of all three designs, we deem it the most efficient - reducing loss factor while increasing compute availability. Since any available compute can be organised, swarm optimises the most efficient allocation of compute. This enables unused capacity to contribute, regardless of its size or location. For instance, spinning unused H100s onto IOTA can contribute to pretraining. The TPU on your MacBook can take a layer. Even the spare capacity of data centres from OpenAI and DeepSeek can participate, taking a full model layer to train at speed - efficiently allocating their unused capacity.
Why IOTA is a part of our future
Now, IOTA’s model versatility means we can absorb and allocate compute efficiently and at scale.
We can dedicate it to training a model and ensure it’s economically viable. Subnet 9’s bandwidth capacity means we can work with multiple models for different clients at the same time.
Our former model competition, SN9’s legacy design, solved the problem of needing to own vast compute yourself - an important innovation used by all subsequent decentralized pretraining systems. Federated learning (as deployed on SN3 and SN38) solves the problem of wasted compute from inefficiency, ensuring that all valuable contributions are retained.
Yet IOTA’s implementation of swarm and pipeline parallelism goes much further. It solves the accessibility problem: anyone, anywhere can contribute to the training of a frontier LLM. It solves the problem of compute efficiency, by allocating compute proportionally in each layer. And it does so with economic viability in mind, by reducing the barriers to entry, both for miners and for start-ups who want to train their own models at scale.
Ultimately, IOTA makes pretraining far more flexible, agile, and economically efficient. Decentralized swarm pretraining presents enormous challenges around bandwidth, compression strategies, and parallelism, but it also requires incentivization - not just to compensate participants for their compute, but also to incentivize and disincentivize quality contributions that relentlessly improve.
Bittensor is a global incentives machine. Attempting a pipeline parallelism implementation of swarm pertaining without it poses significant challenges around convening and rewarding contributions at sufficient scale to train frontier LLMs. Blockchain token incentives can organise incredible amounts of compute - bigger than the largest data centres in the world, bigger than traditional capital allocation methods. Bittensor’s compute-convening and incentivization powers enable pipeline parallelism to scale at speed - and become unstoppable.
Watch the official launch of IOTA on Novelty Search livestreamed from the Louvre at Proof of Talk, and see our whitepaper here.