



This week in the Cosmos: two dashboards, data mixing, and a miner arena
Covering all the recent developments happening at Macrocosmos


Welcome to our roundup, where you can discover all about the recent updates to our five subnets, and learn more about what Macrocosmos has been doing in the last few days.
Co-Founders Will Squires and Steffen Cruz appear on Bittensor Guru podcast, launching season 2

Bittensor Guru, one of the network’s major podcasts for both beginners and power-users, has launched the second season of its series. And to accompany the host, Keith Singery, our co-founders, Will Squires and Steffen Cruz, joined to discuss their work at Macrocosmos, which Keith described in his own words as ‘the most organized of any participant’ in the Bittensor ecosystem.
We’re excited to be a part of his new season, and especially proud to be joining him as he relaunches it.
Keith is a big part of the industry (both as a validator and an educator), so we’re honored to share the digital stage with him.
Check out the full discussion on Bittensor Guru’s own site, Spotify, and X (where you can see the video as well).
SN1 dashboard has been relaunched
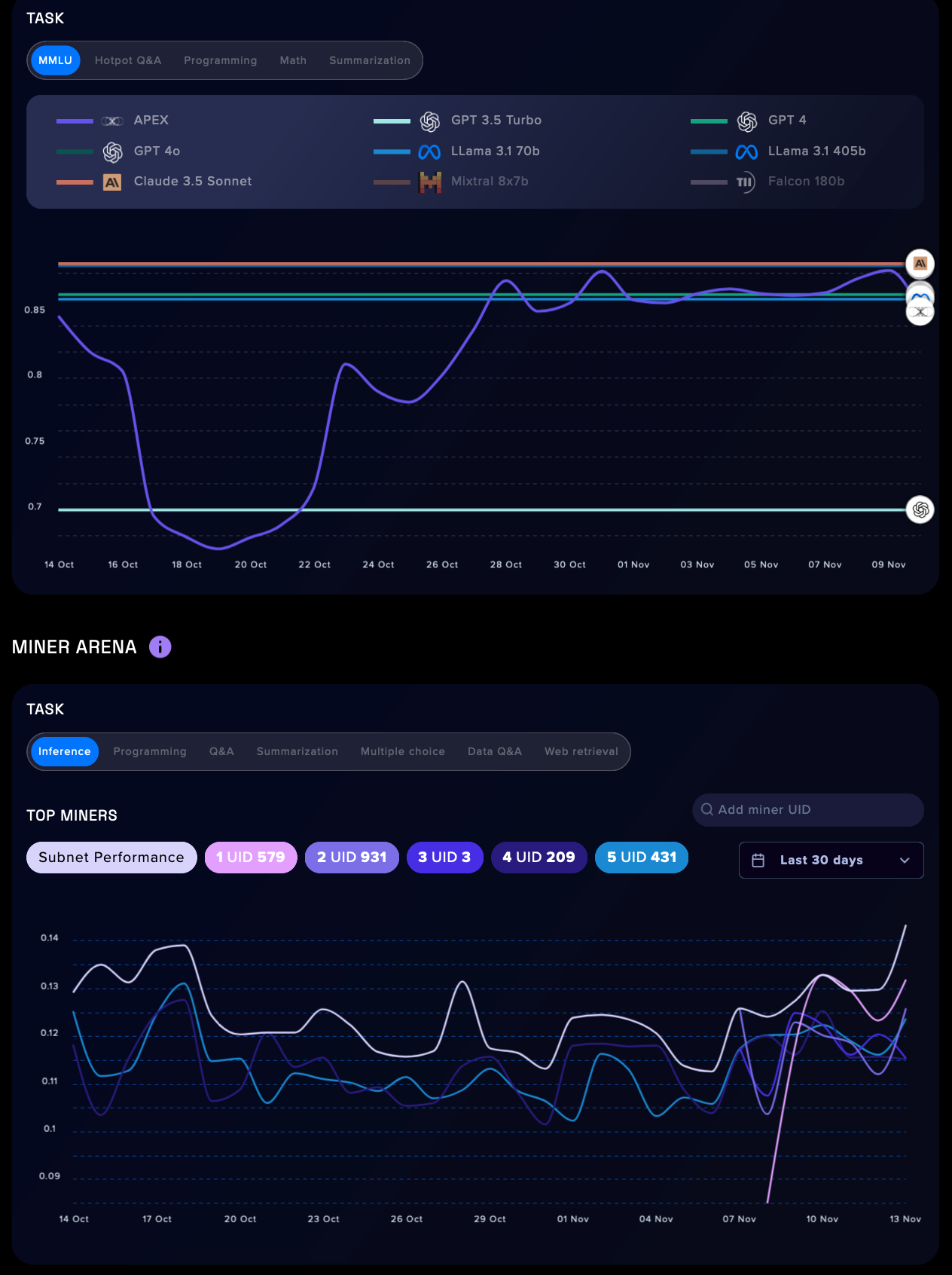
We’ve relaunched our dashboard for SN1, Apex.
This gives you insight into how our subnet is performing against SOTA models by displaying our activity against MMLU benchmarks.
You can check our Miner Arena, where you can see how miners behave on specific tasks, such as inference, programming, summarization, Q&A, and more.
Search for any miner by their UID and then see their activity plotted on the graph.
Lower epsilon leads to more active 14B competition on SN9

To stimulate the SN9 14B competition, we decided to lower the epsilon – this means miners can win the competition by producing smaller improvements than before.
This lowers the barrier to entry for teams to compete, but it also means that winning teams will have to submit new models more regularly to stay ahead.
At present, the epsilon is set to 0.01% (0.0001), however, we’ll soon be moving it to 0.05% (0.0005).
The decay interval will also move from 10 days to 7 days.
We’ll modify these settings periodically, to continue stimulating the competition.
SN13 dashboard has launched

We’ve launched our dashboard for SN13, Data Universe. It displays:
How many rows of data we’ve scraped (currently at 14 billion), along with how many we scrape per day.
How much data we’ve collected across a timeline for both X and Reddit.
The trending topics prevalent within our datasets.
A miner leaderboard, where people can see which participants are currently performing the most activity.
SN25 is set to launch global job pools

Global job pools are coming to SN25, Protein Folding.
Miners can explicitly select the type of work they want to do, based on their own optimized setup and workflow.
Different jobs will come with different rewards, depending on if the query is organic, and how complex it appears to be.
We’ll have the flexibility to programmatically change the incentive landscape, driving the output for TaoFold users.
Mixture-of-Miners: Improving SN1’s Performance

We’ve been experimenting with how models interact with each other on subnet 1, Apex. As a means of improving the quality of responses, we’re testing a mixture-of-agents approach, where different specialized models are called upon to give domain-specific responses. This methodology, which we refer to as mixture-of-miners (MoM), leverages the collective capabilities of models contributed by miners within the subnet, optimizing the overall performance and reliability.
We observed that SN1’s response accuracy improved on average from 71.7% to 81.0% when tested on 4316 samples, narrowing the performance gap with the current SOTA OpenAI GPT-4o, which achieves an accuracy of 88.7%
We saw that a MoM architecture never dropped below the current standard version of SN1.
We found that SN1 is able to outperform current network performance as well as Meta Llama 3.1 70B FP. This brings us closer to competing with SOTA LLMs.
Currently, MoM is in the early stage of development, however, our preliminary results are promising, suggesting this could be what the subnet’s future looks like.
SN9’s upcoming change regarding smarter dataset mixing

SN9 has taken its first steps towards making controlled data mixing a core design choice in model pre-training.
Until now, Our subnet has relied on Refined Web and Fine Web datasets, which are based on web data curation without much control over the data mix. However, SOTA models take a different approach to collecting pre-training data.
This change will come with a new 14B competition which we’re rolling out in due time, with the goal of determining the ideal data mix to bring about a SOTA model.
The competition will be largely identical, but with a range of different data domains. It will also follow a winner-takes-all rewards mechanism.
Stay in the loop for future news
Follow us on X to keep up to date with the latest developments at Macrocosmos – we also invite you to join our Discord server and become a member of our community.