

The Epsilon Experiments: How thresholds incentivise intelligence on SN9
The ‘Epsilon Threshold’ is the minimum improvement on the loss function required to beat an earlier model on the leaderboard. So how does adjusting this threshold change miner behavior?


Subnet 9 is a winner-takes-all competition – only the top-performing model is compensated for their work. We do this to further SN9’s core goal: to produce state of the art pretrained LLMs.
Yet to reliably produce SOTA intelligence, you need more than just an open, competitive winner-takes-all contest. The threshold for improvement is an important variable. It must be calibrated so that it’s neither too high nor too low. Too low, and miners are rewarded for increments that yield no tangible improvement; but too high, and miners will be discouraged from attempting to surmount the incumbent.
We introduce an improvement threshold, “epsilon”, which must be exceeded for a newly-uploaded model to be recognized as the winner. Without this, miners would simply download the leading model and run just a few extra training steps, producing a negligible improvement, and subsequently receive all the rewards. This counterproductive strategy, which we call the ‘negligible improvement strategy’ discourages teams from investing in larger contributions, which are difficult and expensive to produce. Epsilon effectively regulates the rate of improvement on the subnet - but how can we identify the optimal level?
At the beginning of model pretraining, the loss decreases quickly and so the epsilon threshold is easily surpassed by subsequent model improvements. However, later in a competition it becomes increasingly complex and expensive to produce meaningful improvements, which can be observed by the reduced slope of the loss curve in figure 2 after the initial steep descent. Clearly, the epsilon threshold should reflect the difficulty of reducing the loss at the given stage of training.
In most of its competitions, subnet 9 has used a fixed epsilon threshold of 0.5%. This means that a model must lower the loss by at least 0.5% in order to win. This number was determined empirically, and was found to work reasonably well in practice. However, progress was observed to slow down substantially in the 7B parameter competition after the initially productive phase. For this reason, we have recently introduced a secondary experiment which gradually reduces the threshold to 0.1%. Both competitions run concurrently, in order to determine which value results in a higher rate of improvement within the subnet.
As the competition to pretrain a 14B parameter model is set to begin this week, finding the right design for epsilon has become more important than ever. This is because training 14B models is substantially more costly and complex than the smaller models, which introduces more risk to miners.

Dynamic Epsilon
Taking this idea further, we have begun to explore more flexible mechanisms that allow epsilon to be defined dynamically. We call this formulation Dynamic Epsilon. Dynamic Epsilon is designed to promote the following behaviors:
Miners should invest substantial effort and cost into improving models as quickly as possible
Large contributions should receive correspondingly large payoffs
It should not be possible to undermine fair work by copying and making negligible improvements, thus immediately hijacking the rewards
Competitions that do not continue to deliver results should ultimately be discontinued
Our design for Dynamic Epsilon is inspired by the concept of Dutch auctions: Initially, the epsilon is high because that is ideally the improvement we want to see. However, if no improvements are submitted as time goes on, the epsilon function continually decreases, lowering the threshold of improvement and making it easier for miners to upload a new model. Lowering the bar to entry as time goes on - which effectively means accepting smaller and smaller enhancements - prevents stagnation. Otherwise, progress could be throttled by making the competition artificially too difficult. Figure 3 shows several candidate forms for the Dynamic Epsilon mechanism.
In effect, it allows the market to find the right price for improvement. As epsilon approaches this sweet spot, eventually there'll be a bidder capable of submitting an improvement of that size. A decreasing epsilon generally means that the pool of bidders or the accessibility increases until ideally, we find a miner who can step up and give us that model improvement.
This unclogs the competition, preventing long-term dominance by a single unassailable miner. The playing field effectively becomes more level as time goes on - encouraging new entrants, boosting competitiveness, and preventing lock-in.
Dynamic Epsilon also yields another benefit. Its predictability allows miners to plan further ahead, safe in the knowledge that the threshold for improvement will become more forgiving. Thus, they can reliably anticipate their minimum prize (prize pool multiplied by the number of days) which enables them to plan and budget accordingly. We believe that this transparency lowers the overall barrier to entry for the subnet. Especially later in training, 0.5% is a formidable hurdle, and miners know that new models are unlikely to be dislodged at this rate.
For our initial experiments of Dynamic Epsilon we will use the following piecewise linear function:


Linear functions provide a number of advantages. They are intuitive and create a predictable environment for miners to compete. This predictability lowers risk for participants, increasing engagement and driving competition - and therefore results.
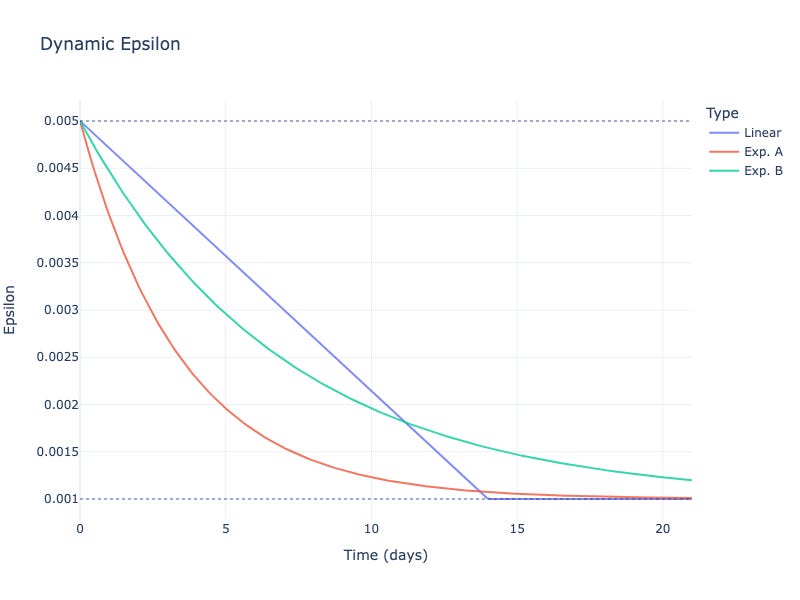
The epsilon is initially high to encourage sufficient level of improvement. But if as time goes on no improvements are submitted, the epsilon function continually decreases, making it easier for miners to upload a new model by reducing the threshold of improvement. Lowering the bar to entry - which effectively means accepting smaller and smaller enhancements - prevents stagnation. Otherwise, the competition’s arbitrary difficulty could discourage submissions and throttle progress.
In effect, it allows the market to find the right price for improvement. A decreasing epsilon generally means that the pool of bidders or the accessibility increases until we find a miner who can step up and give us that model improvement. The playing field effectively becomes more level as time goes on - encouraging new entrants, boosting competitiveness, and preventing lock-in dominance by a single unassailable miner.
While the proposed linear form of Dynamic Epsilon satisfies many of the requirements for a low-friction and high-impact competition, we note the following areas for future work:
Linear functions have predictable properties which can be desirable. However, it may be beneficial to use non-linear functions such as exponentials which decay more quickly initially and more slowly thereafter.
It may be of value to make the minimum and maximum threshold values ε (max) and ε (min) themselves dynamic. For example, making max proportional to the marginal improvement of the submitted model compared to the previous winning model would enable teams to create a bigger moat by uploading larger individual improvements. Additionally, the threshold values may need to depend on the slope of the loss curve so that Dynamic Epsilon is adaptive to the specific training regime.
The rate of decay is currently chosen heuristically. Instead, the slope could also be dynamic, depending on the quality of the top model relative to state of the art models. This way, miners will be incentivized to produce world class results so the slope is reduced and their payoff period is extended.
The implications of these different designs are not yet fully understood, and merit further experimentation.
Overall, our Dynamic Epsilon experiments reveal the flexibility of distributed, decentralized systems. Their collaborative openness increases our sensitivity to miner behavior, and by adapting to this sensitivity we can create mutually beneficial outcomes. That’s what enables SN9 to produce state-of-the-art pretrained LLMs.