

SN9’s smarter dataset mixing: pushing the limits of our pre-training subnet (part 1)
Producing SOTA results with a data-centric approach.


Since switching from a model-centric setup to a data-centric approach, SN9 is currently producing SOTA results. So why did we make this change - and why has been successful?
Model-centric development strategies prioritize the architectural elements of the LLM, advocating that a stronger and more robust foundation will lead to a greater outcome. Data-centric strategies posit that the information built into an LLM is the most significant method of providing quality.
Early on, model-centric approaches dominated machine learning by necessity. It was believed that focusing on architectural choices was the ideal method of creating SOTA models, as this thinking aligned with our understanding of biology and organic intelligence – where the complexity of the brain correlates to the capabilities of the animal or person it belongs to. In the context of SN9, architecture, model parameters, tokenizers, and training strategies are considered under the umbrella of model-centric design.
This method was key to creating models with higher potential. However, as the field evolved, some researchers began suggesting a balance between model-centric and data-centric approaches. They argue that data-centric strategies have the potential to yield more significant improvements, because the quality and diversity of the training data will directly influence the model’s ability to draw accurate conclusions across a wide range of tasks. High-quality data is capable of improving the contextual understanding of an LLM, which makes it more effective. Of course, this is predicated on the data being carefully chosen and treated. Therefore, performance depends not just on dataset size, but also on data quality, management, logging, and cleansing.
That does not mean a model-centric approach is unimportant - in fact, it remains fundamental. Rather, it suggests that the role of data in creating SOTA models may have been undervalued in the industry, and deserves greater recognition.
Subnet 9 and data-mixing
An important factor of the data-centric approach is data-mixing. This is where a model is given datasets that contain information from a variety of sources. This could include web data, code, mathematical equations, scientific documents, multi-lingual content, and much more. In data-mixing, each type of data is presented at a specific ratio or frequency during training, guiding the model’s learning focus and helping it develop a balanced skill set across diverse domains, while avoiding overemphasis on any single area.
Until now, SN9 has relied on Refined Web and Fine Web datasets, which are based on web data curation without much control over the data mix. However, SOTA models take a different approach to collecting pre-training data. For example, Meta reported using a carefully chosen data mix when they were optimizing Llama3’s performance. Web data was sectioned off into domains, such as general knowledge, math, code, and multilingual. The data was then mixed at rates of 50%, 25%, 17%, and 8%, respectively. They experimented with various different mixes and tested on smaller models, with this optimal setup being chosen for scaling up. A similar approach to data-mixing was also applied to Qwen2 when they were pre-training it.
SN9 has taken its first steps towards making controlled data mixing a core design choice in model pre-training. This comes with our newly rolled out 14B competition, with a goal of determining the ideal data mix to bring about a SOTA model. The competition is largely identical, but with two different data sources (FineWeb-Edu2 and The Stack V1 Dedup). It also follows a winner-takes-all rewards mechanism. At present, we’ve released the competition with only one additional data domain, which is for code (with more to be added soon).
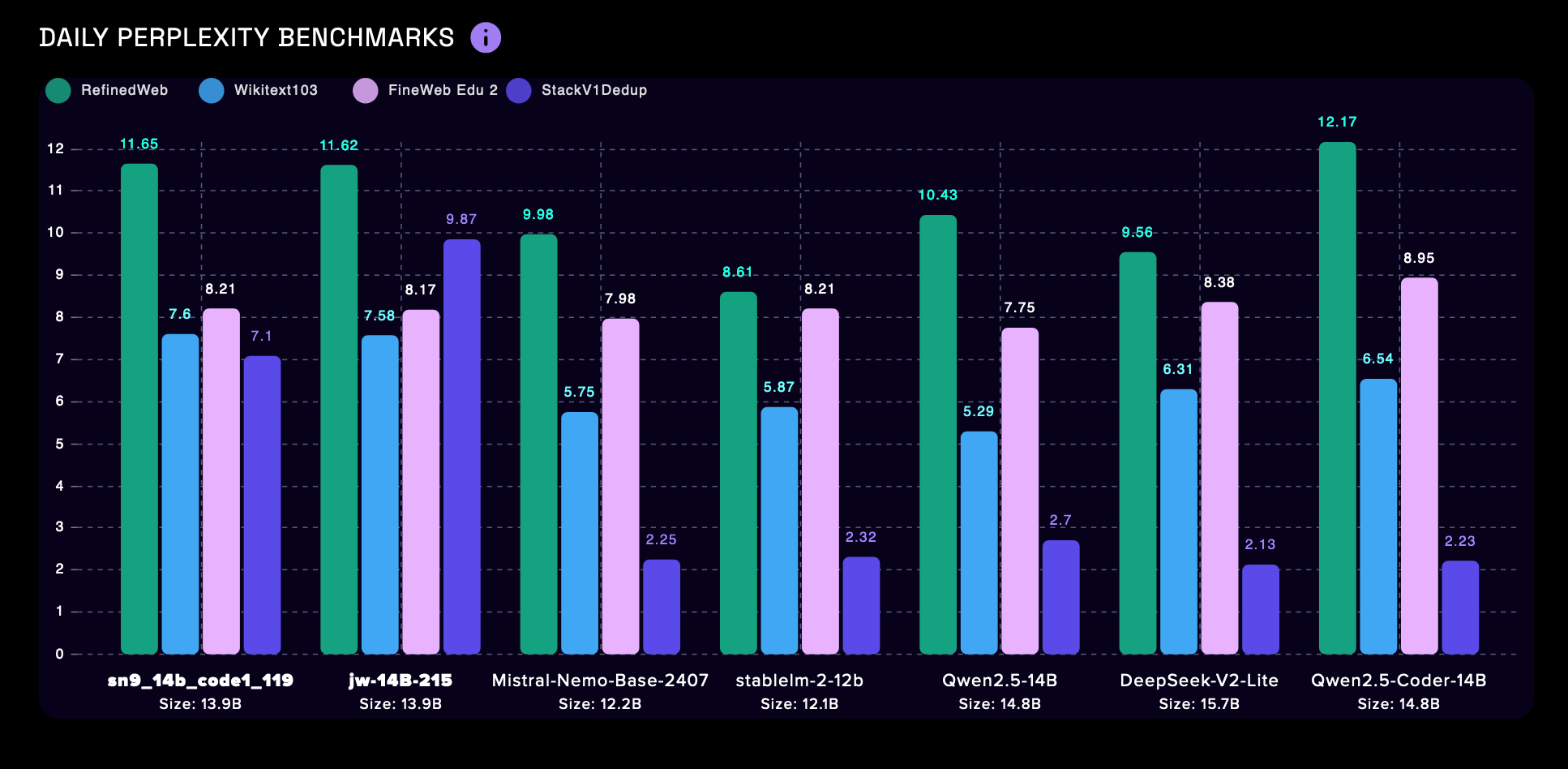
Alongside the new competition will be an updated dashboard, with live performance monitoring to track miners’ progress across each data domain. We’ll also be displaying SOTA benchmarks so that people can understand where these models place against leading LLMs.
Towards a data-focused future on SN9
Emphasizing a data-centric approach is an important step towards creating a mature pre-training space within the Bittensor ecosystem. If we want decentralized SOTA models, then we must understand and adopt the latest thinking in machine learning, and continuously cultivate an optimized environment for decentralized model training. That’s why we will continue to push SN9 to the frontiers of distributed intelligence, even as they relentlessly expand.