

Rebalanced, refined, and SOTA: Our latest dataset mixing results in SN9 (part 3)
Increasing our dataset mixes has provided even stronger outcomes - with our top two models surpassing DeepSeek-V2-Lite, Google’s Gemma 7B, and Mistral 7B. Here’s how.


SN9, pre-training, is undergoing a transformation. Since early December, we’ve been restructuring our subnet to support dataset mixing. After initiating the change, our preliminary findings revealed the subnet to be stronger than ever, with models reaching SOTA levels in our 14B competition. This was just with a 15% mix of math and code, and 85% in FineWeb Edu2.
To further push the subnet and its participants, our recent update now supports an even more varied dataset mix - one that aligns closer to the data mix reported for training Llama3’s architecture. The change hasn’t been out for long, yet we’ve already increased the model quality in our competitions, triggering a flurry of submissions that has boosted SN9’s momentum.
The new and improved SN9
When we first started dataset mixing, we implemented it on a separate 14B competition that ran parallel to our non-mixed competition of the same size. This was so that we could benchmark the new results against the original setup - and, if they proved preferential, it also allowed for a smoother transition for participants.
However, once we found that our dataset mixing winners were beating our non-mixed winners, we decided to abandon the older one, to single-mindedly serve SN9’s core purpose: to pre-train SOTA models. In support, we upgraded our 3B competition to support dataset mixing.

This means that as of release 5.0.0., all our competitions support dataset mixing. Our current delineations are 55% general knowledge (constructed from FineWeb and FineWeb Edu2), 35% code, and 10% math and science - echoing Llama3’s dataset mixes, although not identical in its separation and categories.
Results from the upgraded SN9
We observed benefits immediately after upgrading. For starters, both our 14B and 3B competitions are experiencing a spike in submissions. This is partially because of renewed excitement around the competition, increased exposure to our subnet, and several changes we’ve made to how the epsilon lower bounds work. But we believe it’s also because dataset mixing has breathed new life into the subnet, sparking greater innovation and participation.

We’ve also compared our SN9 winners to the general model-training landscape. In the past, we could compare simply to our own non-mixed competitions, but since disbanding them, we’re unable to do the same. Instead, we looked out to the Bittensor ecosystem - where our 14B competition models outperform those in Subnet 29’s 00 20B competition. It’s worth remembering that SN29’s competition doesn’t support dataset mixing, and only uses FineWeb Edu2 - both of which underscore the importance of mixing in boosting performance.
However, SN9’s models achievements extend beyond Bittensor. On MMLU (N-shot=5), our top two winning models not only beat SN29’s up-to-20B models, but they surpass DeepSeek-V2-Lite, Google’s Gemma 7B, and Mistral 7B. Therefore, this puts our winners well within the SOTA range.

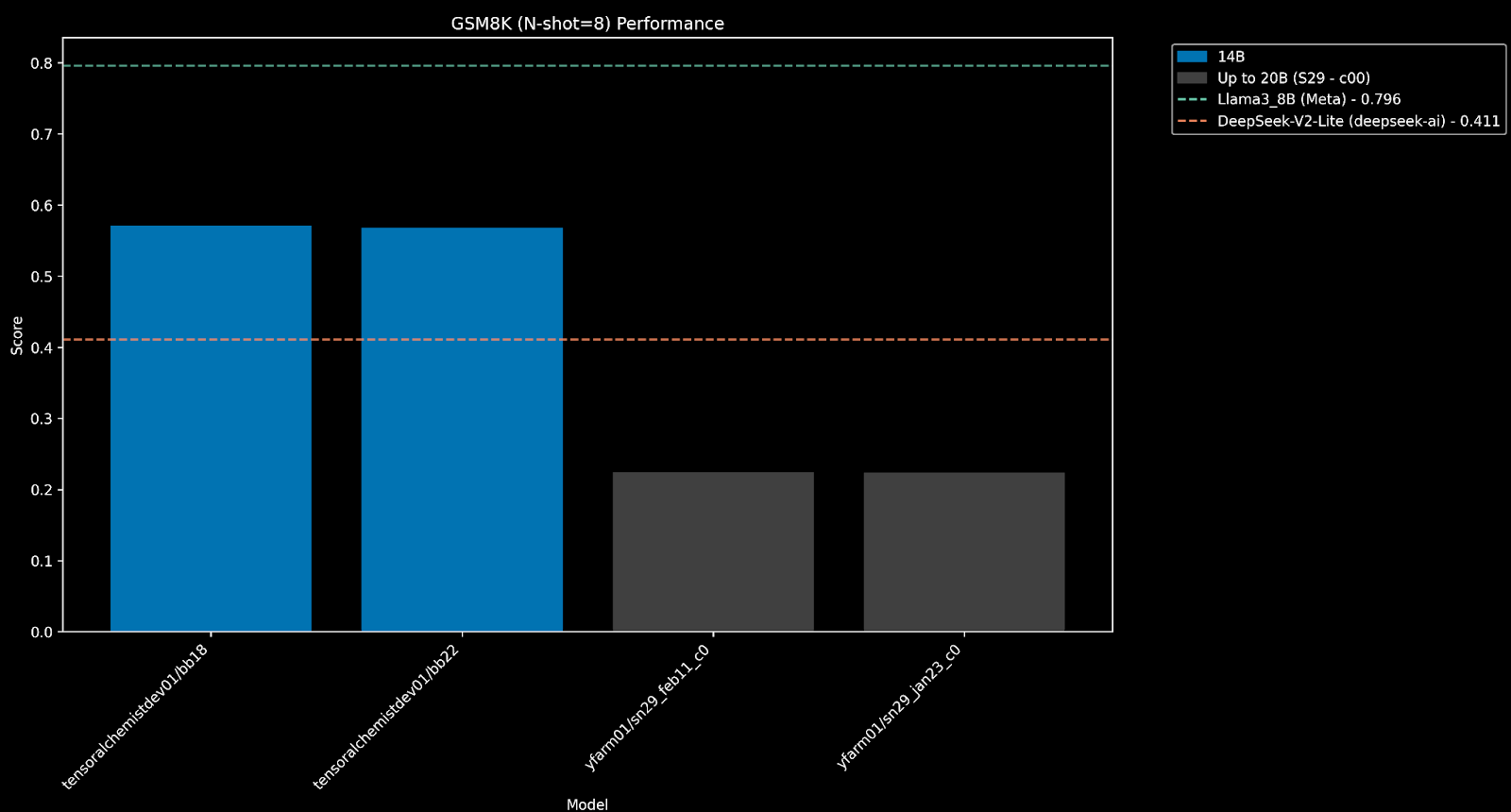
Using the GSM8K (N-shot=8) benchmark, our top two winners beat SN29’s by a wide margin, as well as surpass DeepSeek-V2-Lite.
However, when it comes to the ARC Challenge, the comparison is tighter. We still score higher than the SN29’s models, but the race is much closer.

Up next for SN9
Not only are we proving that dataset mixing is viable on Bittensor, but SN9 also demonstrates how it can stimulate competitions, encourage innovation, and excite the community. What started out as a mere experiment into different pre-training architectures, has evolved into a fundamentally stronger subnet.
We’re now confident that, beyond volume and quality of public data, SN9 has no limits. However, most proprietary models don’t reveal their exact datasets, closing the door on open-source alternatives. Therefore, if we want to compete by continuously producing SOTA results, we must expand our repertoire of open-source and accessible datasets, and scale upwards so our models can be well-fed with information. Training with synthetic data is also becoming a mainstream approach in machine learning, and so this’ll be a part of our future plans, too.
By proving that the very best models can be built on Bittensor, we can elevate the entire protocol and push SN9 to the top of the LLM-training ecosystem. The success of dataset mixing is a step towards making that vision a reality.