

Monsters, vampires, and X-rays: subnet 9’s Halloween deep dive
Revealing the ghoulish, trick-or-treat tactics miners are incorporating into our pre-training subnet

It’s late at night. The wind is howling and the rain is lashing the windows. And you’re sitting, once again, at your dimly-lit desk, combing through your routine benchmarking experiments.
Suddenly, something catches your eye. A strange result in one of the sub-competitions. It seems that the top 7B model is performing exactly as well as the winning 14B model.
‘This can’t be right,’ you mutter as you double-checked your code. ‘It must be a bug.’

Your hand reaches for the last of the grim black coffee, your weary eyes scanning the codebase again.
But you quickly conclude that your logic is intact. Your eyes scrolled frantically across the screen, your mind racing. ‘But how can such a large model be so terrifyingly terrible?’, you gasp. You realise your hands are shaking. And so you take a deep breath. You choose to swallow your fear and hunt down the monster models.
You open the model files and peer into the weights. Billions of bits and bytes pour into memory, your laptop groaning under the strain. As the histograms begin to take shape, you immediately sense something is awfully wrong. A mighty clap of thunder jolts the coffee from your hand and nearly topples you from your chair. Slowly, your eyes lift and you let out a scream – a flood of hideous bilge! Weights, oozing weights, each layer uglier than the last!

It’s Halloween - so we’re sharing our recent findings of ‘monster models’ and ‘vampire models’ in SN9. As well as exposing these miner strategies, we’re also showing our ongoing observability research at Macrocosmos.
Bittensor is the world’s leading decentralised AI platform. As such, teams in Bittensor are pioneering the emerging field of game theoretic AI. This means tackling novel problems confronting the inherently adversarial nature of the decentralised systems we build. Unlike centralised systems, where all components are fully controlled by a single authority, Bittensor miners employ strategies which aim to maximise their rewards while minimising their efforts.
Recently, we have been carefully analysing the models in our Subnet 9 14B competition, so that we can understand how miners are operating. In particular, we’ve been curious about model quality and the way miners interact with the competition. We've identified two noteworthy strategies: model inflation (‘monsters’) and model copying (‘vampires’). Exposing these strategies requires a powerful visual tool that we call X-ray.
In order to quantitatively examine the models in our competitions, we extract the trained weights in each layer and summarise these weights using percentiles. Percentiles capture the shape of a distribution in a compact set of numbers. When a distribution is very tight, the percentile values are all close together, and when a distribution is broad they are more spread out. We then draw lines which connect the percentile values of each layer in the model, producing a visual fingerprint of the weights. This plot, which we call a model X-ray, enables us to inspect the ‘shape’ of an entire models’ weights at a glance and also compare different models in terms of their underlying weights.

The ‘monsters’: Model Inflation
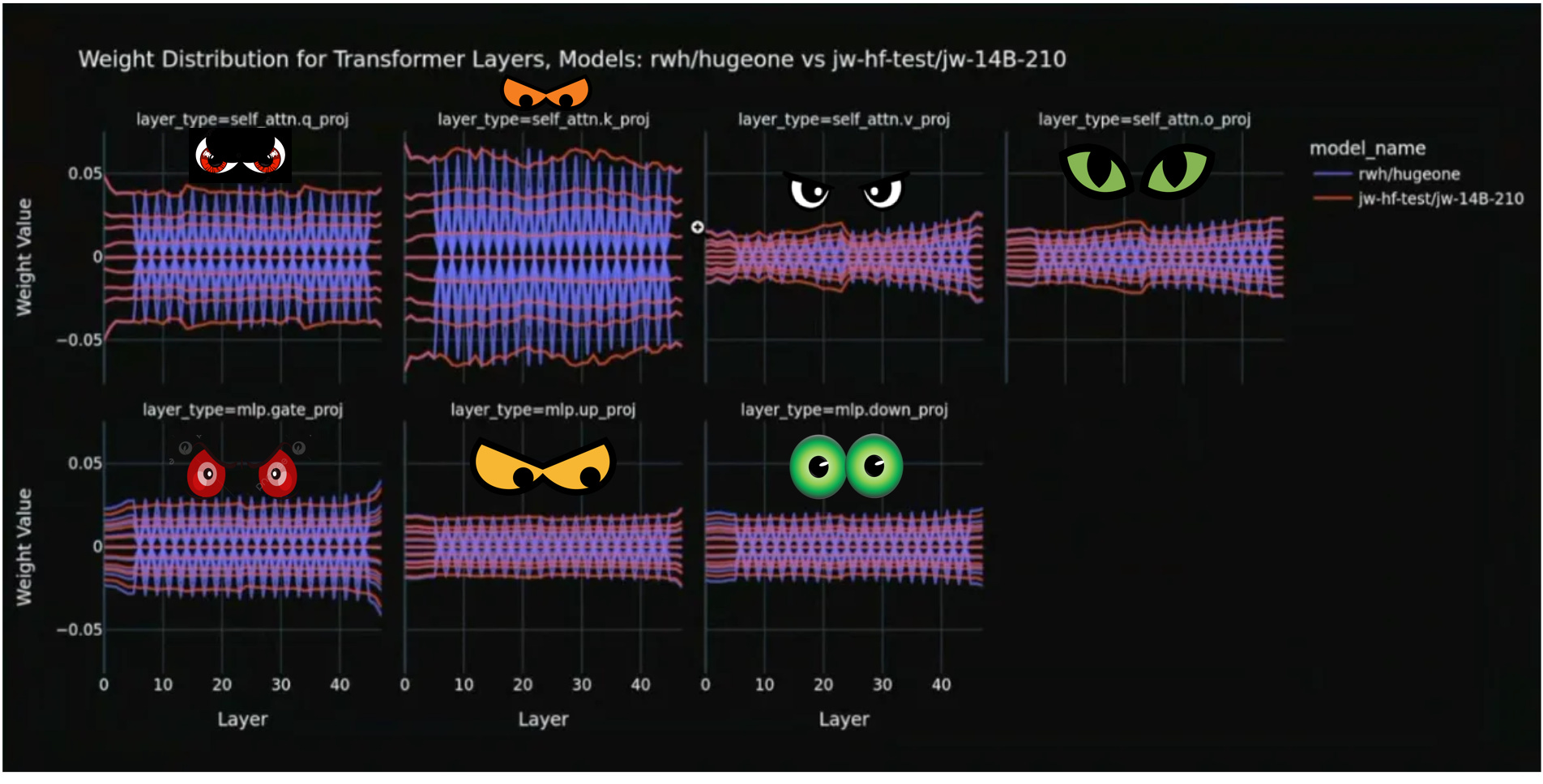
After analysing some of the models running on our 14B competition, we found some unique abnormalities. Some models had unusual weight distributions for their transformer layers. Here, you can see a spiking pattern in the X-ray of rwh/hugeone. This is atypical for how a model should be running within our competition, as the weight values should essentially form a line which dips and rises with less drastic activity across the model layers.
Such a jagged formation suggests these models are performing parameter padding, or have inactive parameters. If they are padding their parameters, meaning they are adding additional zeros to their model, then it indicates they are dilating a model that is essentially smaller than a 14B.
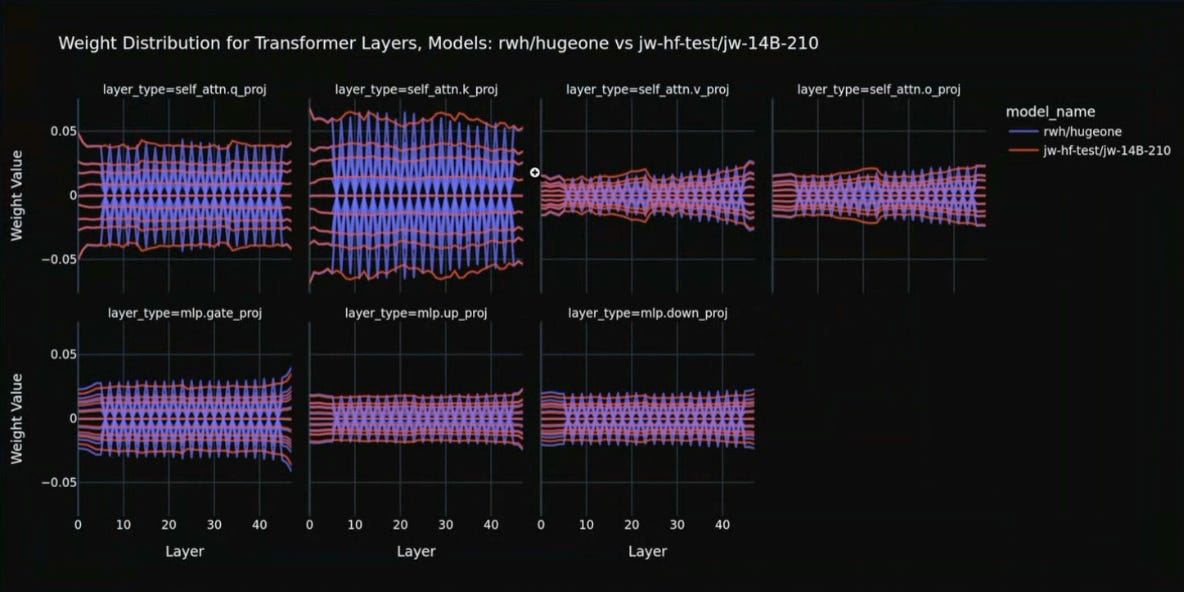
We also found other strange activity within different models. Some models do not exhibit these jagged lines, but instead, some weight distributions for transformer layers simply cease fluctuating and continue with a flat trend. This, too, suggests some level of inflation, where parameter repetition may be involved, allowing smaller models to masquerade as 14Bs.

Our investigation uncovered that many models in our 14B competition were running exactly the same as some 7B models, which solidified our assumption that dilation was occurring. The supposed 14B models contain the jagged lines, but when you scale them to the same size as the 7B models that these miners once ran, you can see their peaks align relatively well.
We could find data for the 7B models because we previously ran a pre-training competition for them, although it is currently inactive. If the 14B model was truly taking advantage of its extra parameters, we should see a more significant level of divergence - which, however, is not the case.
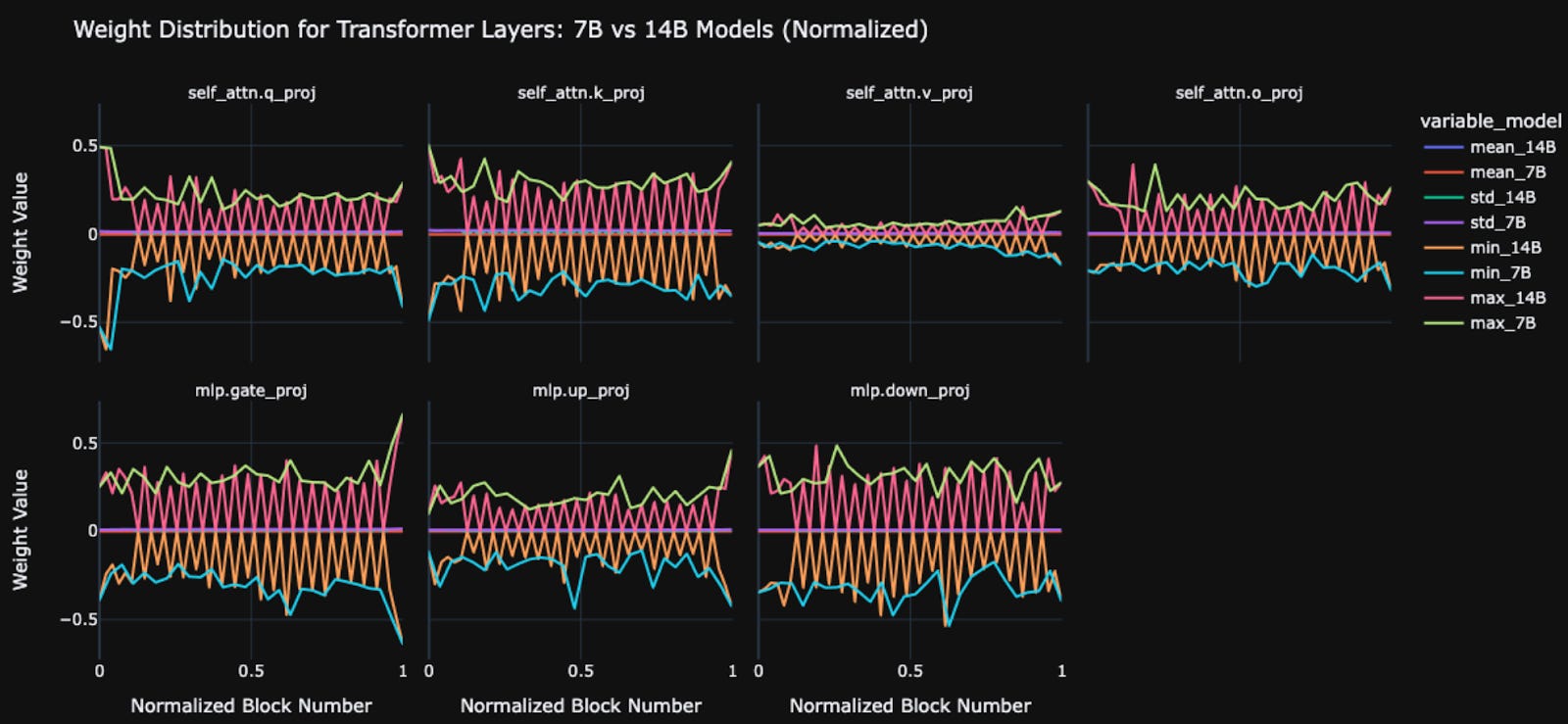
It is fair to look at this graph and present the case that the peaks of the 14B model do not perfectly match with the lines on the 7B, and so this could mean they are not exact copies with padding. However, the reason they are not in exact alignment is because we had to normalize the plots so that the two could fit within the same space on the graph.
The ‘vampires’: Model copying
After x-raying several models, we found that many of them were engaging in model-copying. This is the process of uploading a previously created model into the competition. It's visible due to how the graphs overlap so closely to each other. In some instances, you cannot even see the differences between them. The more similar they are, the more their lines collapse into one.

It’s worth noting that model copying is an entirely legitimate method of trying to win a competition. A core aspect of SN9’s setup is that its open-source nature means people are encouraged to borrow from other models and improve on them. Therefore, the process of creating a SOTA model becomes a collaborative effort where improvements are iteratively made. This ethos is echoed throughout the Bittensor ecosystem.
The caveat, however, is that we want miners who copy models to make some improvements to them, rather than simply take them as is. In some scenarios there has been direct copying with practically zero amendments. This occurs, in part, on the 14B competition, but you can especially see it in the 3B competition.

Returning to the 14B competition, what’s fascinating is some miners appear to be copying models that are parameter padding, and then further padding their variation. As x-rays of models are still not common practice, it is unlikely the copiers knew they were taking inflated models, but regardless chose to inflate them further.

When it comes to model copying, the best way to award somebody is to see who uploads first. We can easily do that by checking the block order for when the models are uploaded.
Model merging, an emerging sub-field in pretraining, provides a way for multiple models to be combined in order to improve them further without extensive additional training. It has the potential to accelerate our competitions and drive better results, which is why we are excited to continue exploring this novel approach.
What comes next?
These two findings may overlap, but they are fundamentally different, and so our approach to them differs to match.
Model copying is in the spirit of open-source competitions within the Bittensor ecosystem - even if some miners copy models without enhancing them. The idea of building on pre-existing models is, in our opinion, one of the best ways of achieving a SOTA model.
Model inflation, however, is a different matter. While there is nothing inherently wrong about uploading a 7B in a 14B competition, it does bend the rules a little, as it means the competition is no longer testing for the models it was designed for. While these are technically 14B models, as the padded parameters are still parameters nonetheless, we find it to be a poor engagement with the subnet.
Therefore, we are updating the architecture to hopefully prevent this activity. While there definitely are merits to running a 7B model and having it win in a 14B competition, it goes against the telos/purpose of the competition, which is to create a SOTA 14B.
Fortunately, such models are significantly weaker than fairly-trained models, and are easily beaten.
We are excited to be deploying our new X-ray tooling onto our SN9 dashboard. That way, people can actively see how models compare to others under the hood. This will shine a light on both model copying, and models masquerading as larger than they truly are. This is not to discourage copying, but rather to give people insights into what is happening within the competitions.
And after all, the tried and tested way to kill vampires is actually rather simple: to shed some light.
