

Mixture-of-Miners: improving SN1’s performance
Experimenting with decentralized architectural changes to the LLM landscape

Can layered architectures outperform singular models - and if so, how can we harness them on distributed systems? We’ve been experimenting with how models interact with each other on subnet 1, Apex.
As a means of improving the quality of responses, we’re testing a mixture-of-agents approach, where different specialized models are called upon to give domain-specific responses. To merge these diverse responses into a high-quality single output, we employ an aggregator Large Language Model (LLM) to ensemble the miners’ responses. This methodology, which we refer to as Mixture-of-Miners (MoM), leverages the collective capabilities of models contributed by miners within the subnet, thereby optimizing the overall performance and reliability of the subnet.
A primer on Mixture-of-Agents
Before we delve into our findings, it’s important to understand how Mixture-of-Agents models work. This is where different models or even agentic workflows are selected to respond to certain queries. The idea is to leverage the collective strength of multiple miners to achieve the best aggregated results. It’s an alternative to creating a highly generalized model that is meant to be a jack of all trades.
A layered architecture, where multiple models or workflows are aggregated into one model, can outcompete a monolithic structure (which is how SOTA LLMs currently operate). The team at Together.ai produced some fascinating results with a mixture-of-agents approach, which inspired us to investigate first-hand.
Acting as an additional layer on top of the standard LLM setup, this approach should increase overall intelligence, with each miner benefiting from their own built-in agentic workflow. This would therefore be a hybrid of both data-centric and model-centric approaches.
At the core of a Mixture-of-Agents structure is an aggregator, which takes miners’ responses as auxiliary information to generate the new high-quality aggregated response. Think of the aggregator as somebody who does not exactly know the answers to a question, but does know who would have the answer. Its main role is to be an intelligent connector. Concurrent efforts by Nous research have already confirmed that ensembling is a promising avenue. They incorporated this into their language model, Hermes 3.
Macrocosmos’ approach: Mixture-of-Miners
Our decentralized infrastructure allows us to leverage diverse models within the subnet, each contributing domain-specific knowledge and agentic workflows.
By employing the MoM architecture as a secondary inference layer after initial miner responses, we optimize the final output quality through the aggregation process (see Figure 1). The MoM architecture operates in two phases:
Initial miner responses, which provide a range of perspectives,
A secondary aggregation phase, where an LLM aggregates these responses under the guidance of the system prompt.
For our aggregation, we use Llama 3.1 70B 4-bit, as it performs well in MMLU benchmarks.

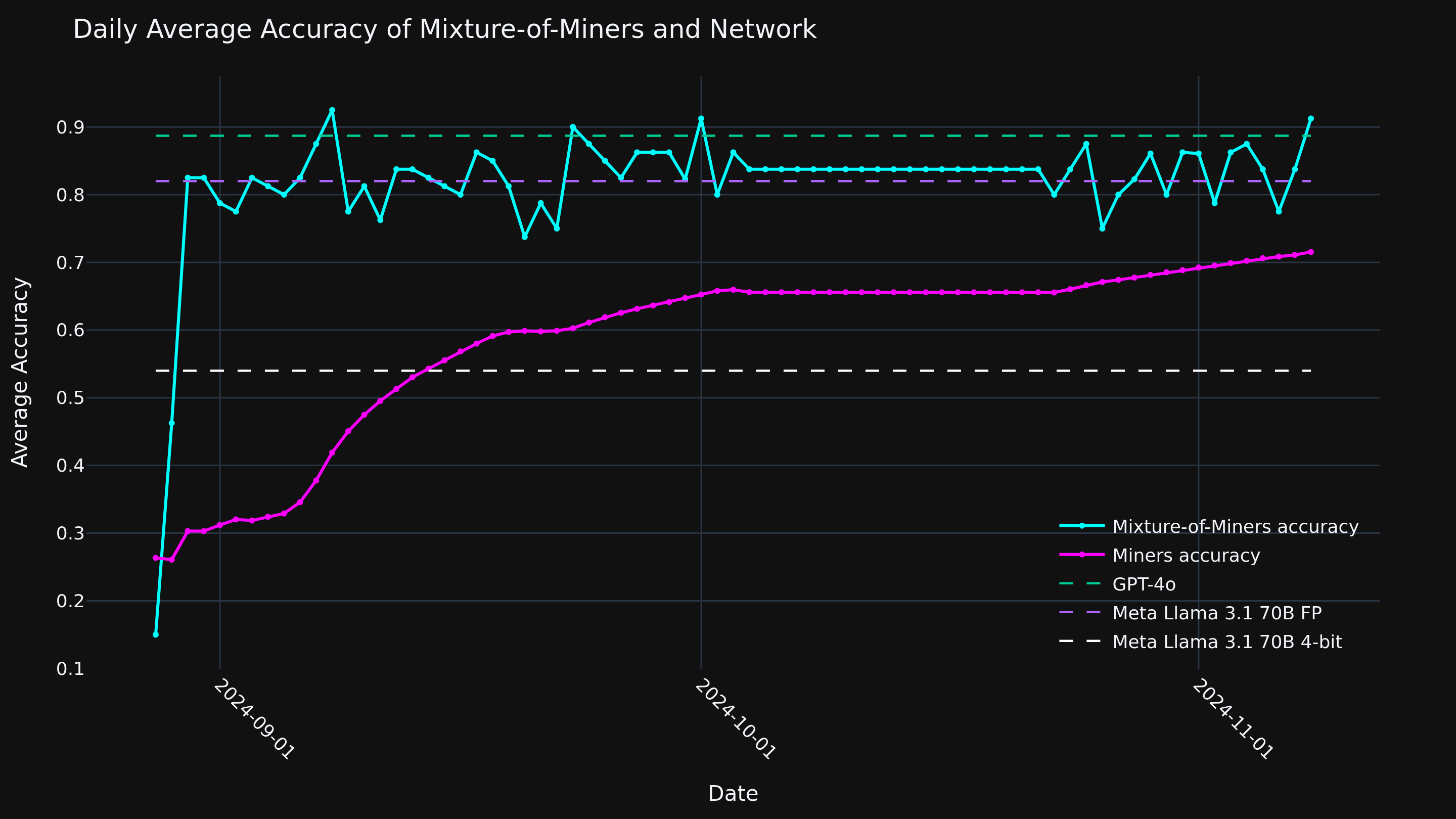
To evaluate the effectiveness of the Mixture-of-Miners approach, we ran experiments on the MMLU benchmark, measuring the relative performance of MoM against raw miner responses. Our findings indicate a significant improvement in accuracy, with MoM-enhanced responses achieving an average accuracy of 81.0% compared to the baseline of 71.7% (see Figure. 2). This improvement narrows the performance gap with the current state-of-the-art OpenAI GPT-4o model, which achieves an accuracy of 88.7%, and demonstrates the potential of MoM architecture in enhancing response quality.

The future of SN1 and decentralized LLMs
For a long time, the industry has speculated about how - and when - closed-source AI models will be outperformed by their open counterparts. However, at present, they still reign supreme on benchmarks. Integration of innovative architecture demonstrates the potential advantages for decentralized models, and helps to make the goal of an open-source SOTA AI experience a reality.
Mixture-of-Miners is a process that works well in a decentralized setting, and so we’re excited to showcase our findings as an indicator of what the open-source world can achieve when joined together. Currently, MoM is in the early stage of development. However, our preliminary results are promising.
Mixture-of-Miners also offers a new way of approaching LLM design that could solve some of their current-day issues. Many high-performing models, while impressive, have serious limitations – they output tokens one at a time, confined to a fixed context window, lacking the ability to perform deep reasoning or plan ahead. This is naturally restrictive, as it leads to the common problem of LLMs producing initially strong responses, only for them to become riddled with inaccuracies and inconsistencies down the line.
In reaction to this, novel approaches are being developed, such as increased test time computation (which GPT-o1-Preview and Nous Forge apply), and using different miners/agents to tackle topics related to their specialized knowledge. The result is higher accuracy and greater responses - and a call-to-action for new LLM design choices that can push industry standards forward.