

IOTA: Bittensor's biggest pretraining breakthrough is here
Subnet 9 is now the home to the world's first ever model parallel and data parallel incentivized trustless pretraining protocol - proving Bittensor’s potential to incentivize truly decentralized AI.


Pretraining is crucial to AI. Yet its vast scale and inherent complexity render it all but impervious to decentralization. The vastness of the datasets and processing power needed to pretrain SOTA-level models favours concentration of resources, which enables the economies of scale and eases communication between machines and devices during the training process.
However, if we’re serious about decentralized AI, we must decentralize training at scale - otherwise, the possibility of truly trustless and distributed training will never become a reality.
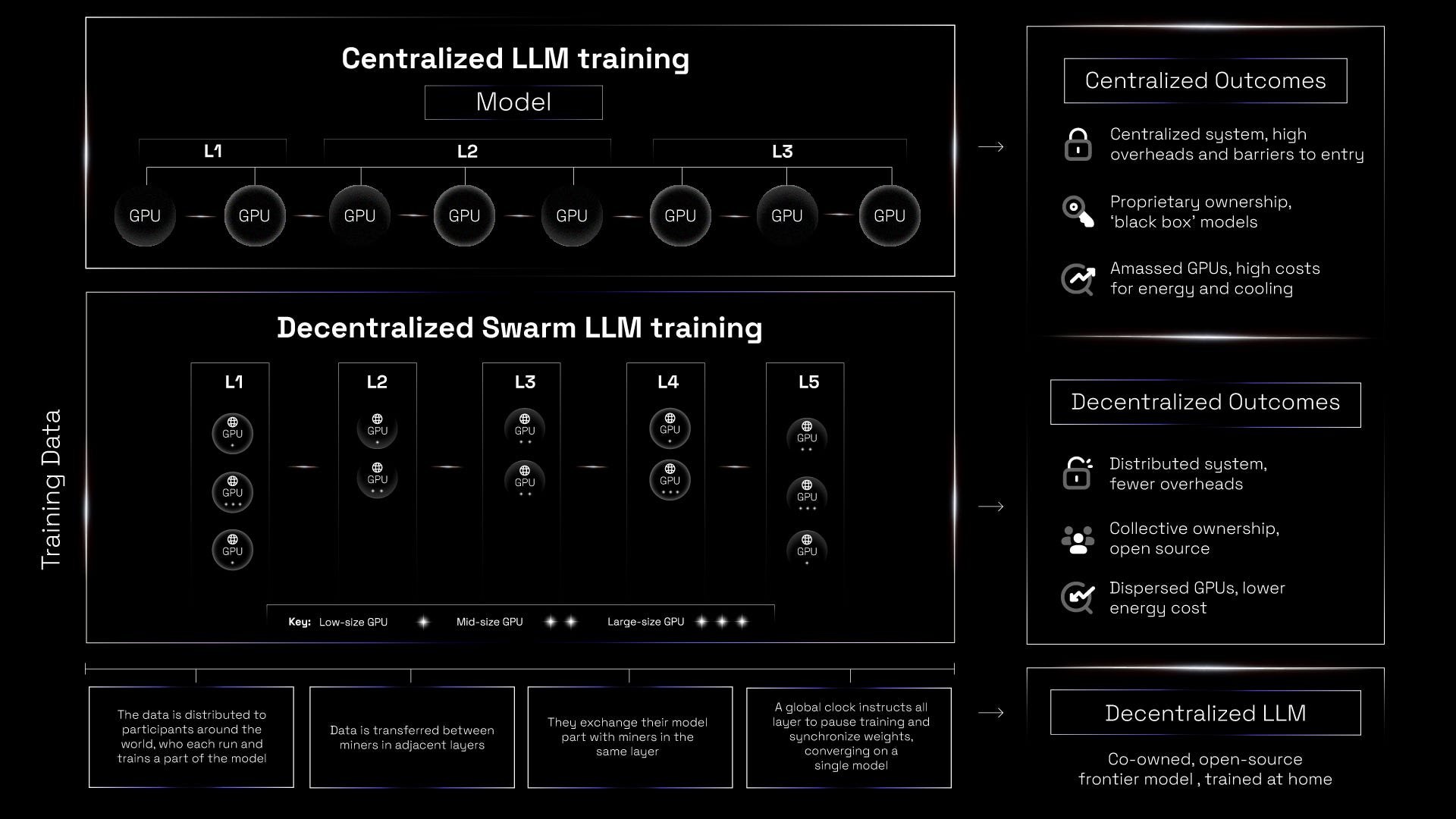
That’s why we relaunched Subnet 9 as IOTA: Incentivized Orchestrated Training Architecture, enabling trustless, incentivized swarm training.
Broadly, swarm refers to multiple nodes working towards the same goal - but IOTA harnesses Bittensor to overcome the challenges of trustless incentivization and reward to deliver a swarm training strategy that scales. It allows globally distributed participants to train AI without needing to run the entire model on their machine, widening access and reducing barriers to entry.
It’s a technical feat for the protocol - but IOTA is also a significant step towards Bittensor’s original intention of creating a competitive, decentralized alternative to proprietary models at SOTA levels. That’s exactly what IOTA achieves.
Overcoming technical challenges
Swarm-like strategies have many advantages, yet their technical complexity has prevented most projects from considering them a feasible approach. Building it on Bittensor - dealing with free riders, incentivising the right behaviour - is even harder.
One of the biggest obstacles concerns communication and bandwidth. Swarm learning requires frequent model synchronization; even in a 30B model, for example, transferring and synchronizing model parameters across synchronized nodes demands enormous bandwidth. If you train in-house, the speed of transfer between GPUs in the same datacenter—often connected via InfiniBand at over 200 Gbps—will be orders of magnitude faster than distributed alternatives. By comparison, household internet typically offers less than 1 Gbps - unsuitable for this level of workload. Without optimized model compression and decentralization strategies, these limitations cannot be overcome.
Bandwidth is one limitation, but it’s exacerbated by another: computational storage. The size of the files being transferred during a training run is huge - and the varying nodes of decentralized networks are not uniform. Some nodes can’t handle the computational loads, memory demands, and storage capacity of massive models - limiting access and complicating orchestration.
Moreover, these nodes must do more than handle the computational demands; they must reach consensus on model updates. However, blockchain networks always involve latency - meaning that consensus can cause bottlenecks, disrupting the real-time iterative process of training.
Synchronising work between different nodes is hard, but orchestration is harder if contributors don’t communicate between themselves. On a permissionless protocol, that’s a challenge. Orchestration poses two questions: how do you manage untrusted, incentivised contributions, and how do you harmonise contributions from differing hardware types, volumes, and systems, so that miners of different sizes can participate?
From incentive design to developing economic rewards commensurate with the high operational costs of IOTA’s demands, ensuring that miners or validators remain incentivized to maintain quality participation in the training becomes complex - especially as model sizes increase.
Why IOTA intelligence is different
IOTA holds an important advantage over other forms of training: as it scales, it becomes more efficient. At 3B or 7B, the communication bottleneck is too hard to overcome - but as you train larger models, it becomes viable.
When training a decentralized model on IOTA, each participant or node must understand the scope of their task, and communicate with the orchestrator via a hub-and-spoke system. It also puts the onus on miners to keep compute cost low - widening access, driving efficiency, and allowing for scale at speed.
IOTA also circumvents conventional challenges around efficiency, complexity, and engineering that confront centralized training systems. It never runs the risk of overwhelming the energy grid. Nor must it grapple with the implementation of vast cooling systems. As with cost of compute, these advantages grow more acute with scale.
Comparing the costs of training major models shows that a model twice as good ends up costing x10 more than its predecessor. Swarm-style systems like IOTA may well be the only way to train large models in a cost-effective way and avoid these spiralling costs.
Why Bittensor is best for IOTA
Bittensor resolves these problems - but it also offers critical advantages for hosting swarm training. Achieving consensus in swarm training involves blockchain-based validation of every training step. Given large model updates, consensus becomes resource-intensive and slow. Most consensus mechanisms are unable to facilitate swarm training at scale, as most are too limited or unproven - but Bittensor’s Yuma consensus is able to do so.
While other decentralized training projects must confront the complexity of incentivisation for the first time, Bittensor is an incentivisation network - and our experience of designing, honing, and iterating incentives and reward functions enables us to navigate the high operational costs due to computational power, storage, and bandwidth demands.
Bittensor is already proven at globally convening and coordinating compute. To achieve swarm training, large-scale decentralized networks must handle node churn and intermittent failures without corrupting the overall training state. Maintaining a consistent state across billions of parameters requires robust fault-tolerance mechanisms - adding further complexity and overhead.
Sooner or later, other projects must confront the problem of orchestration and trust. At that point, they must either build their own protocol from scratch, or establish a partnership with a coordination layer. Either way, this is a critical and complex process, and if it isn’t confronted early, it can destabilise progress.
By coordinating and orchestrating participants, Bittensor is the best fit for deploying swarm at scale - as demonstrated by the fact that Macrocosmos has implemented IOTA’s swarm breakthrough at such speed.
Understanding Macrocosmos’ IOTA
Swarm intelligence isn’t a new concept - but our implementation does deploy a unique architecture.
Model parallelism
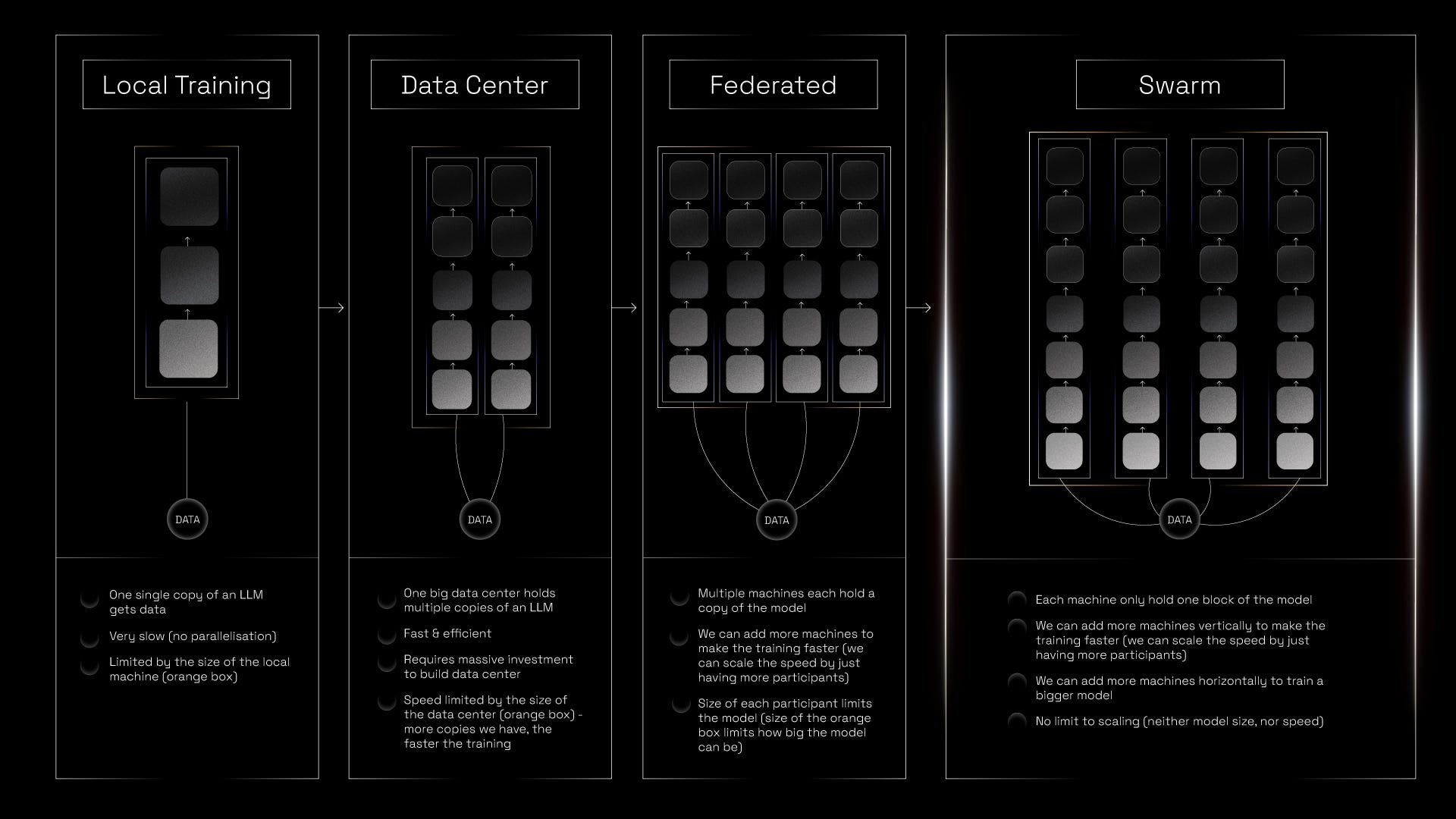
In many swarm architectures, each participant maintains a local copy of the full model. They train it independently on local data or assigned tasks, and then share their updated model parameters with a central aggregator, or among peers. These updates are then combined (e.g. averaged or optimized collectively) to produce a refined global model.
However, this setup becomes resource-intensive and costly when working with bigger models. Training large machines demands significant computational power, memory, and time, which is taxing for each participant to store and train individually. The maximum size of the model you can train is limited by the smallest miner.
For IOTA, we implement model parallelism - our model is parcelled and distributed across participants. A model has a neural network made up of multiple layers, each containing several neurons. These neurons perform simple computations and pass their outputs to the next layer. Typically, the more parameters a model has, the more neurons and layers it contains, which increases its capacity to learn complex patterns. After splitting the model into stages of differing several layers and neurons, we assign participants (miners) to different areas. They’re then given smaller chunks of the overall model to train.
The upshot is they don’t need a full local saved version, just the part they’re working on. This is less labor intensive, and therefore has a lower financial barrier of entry for contributors. We’re able to leverage users with both low and high levels of compute, creating more overall power. Many other swarm setups rely exclusively on those with large quantities of compute, reducing their pool of participants, however, we’re building an inclusive system that casts a wider net.
Data parallelism
Just as model parallelism parcels up the neural network, allowing miners to work on separate parts at once, data parallelism splits up the training data so it can be trained on individually.
This data-parallelism allows miners to work on disjointed parts of the training data, across different batches of the same connected model. The data flow is then coordinated by the system itself. With everybody working in coordination, the process can be faster and less intensive. This enables multiple batches of data to be processed at the same time, across different batches of the same connected model. By using both data and model parallelism, IOTA maximises both decentralization and accessibility.
Forward and backward passes in IOTA
For the model to produce results, it requires each individual participant to pass their updated chunk of the model forward to the next stage (or cluster of layers). An input enters in the first layer (in this case a set of tokens - chunks of text), and the model will predict the next token. This continues until you reach the final stage. Once the input makes it through the entire model, layer per layer, the last layer produces a prediction.
This produces a learning signal, because we now know what the correct prediction is. We then propagate the feedback layer by layer back all the way to the first layer, and adjust each model parameter ‘proportionally’ to how wrong the prediction was. So each participant at the end must pass their data back through the same route they passed it forward. These backpasses are also known as backpropagation. The purpose is to calculate the contribution of each part to the final result, so that weights within parameters can be adjusted accordingly.
Rewarding miners for computing power
IOTA’s architecture favours those with higher bandwidth and stability, and stronger GPUs. The greater your GPU setup is as a miner, the more you’ll be rewarded. However, even if you have a T4, an A100, or anything in between, you’ll be working on the same collective goal: building a distributed decentralized AI model. This is not a winner-takes-all reward scheme: and so everybody will be rewarded for their activity.
A new era of training on Bittensor
Training has always been a core focus at Macrocosmos. Swarm intelligence marks a new chapter - not just for us, but for the protocol as a whole. In the past, our training subnets were designed as battlegrounds, where miners competed against each other to upload the best models and take the highest rewards.
This was successful in incentivising SOTA open-source pretrained models on Bittensor, but the models weren’t actually created in a decentralized way. The competitions and rewards were handled via decentralization, but the actual model-building was handled separately.
With IOTA, we’re adding a new dimension of distribution. Not only can participants around the globe join permissionlessly, but they all come together to build modular models and get rewarded as a collective. Operating SN9 and SN37 provided us with the knowledge and inspiration to now orchestrate this novel training process, and it’s thanks to our miners, validators, and the wider Bittensor community that we’re able to implement this advance.
Swarm is the future of decentralized training. And by harnessing Bittensor’s superpowers - incentive design, efficiency, and coordination at scale - we demonstrate the network’s critical position in making that future a reality.
Watch the official launch of IOTA on Novelty Search livestreamed from the Louvre at Proof of Talk.