

Distributed learning for decentralized LLMs: preliminary results
Breaking down our federated learning experiment.


Decentralization drives our work at Macrocosmos. For Bittensor to prove its worth against competitions, its subnets must demonstrate distributed solutions to key challenges, both within machine learning and beyond. This motivates our efforts throughout our five subnets - and it’s why we’re exploring distributed learning for LLMs.
What is distributed learning?
Distributed learning is a machine learning approach where a model’s training is split across a range of nodes or participants. These actors collaborate to train the model, where they can share data, computational power, or both. It disperses the process of creating models, meaning that activity doesn’t happen entirely in one homogenous place. The upshot is it can speed up the model-training process - as multiple sources can contribute in parallel, models can handle larger datasets with ease by partitioning the data across participants.
The specific form of distributed learning we’ve investigated is federated learning for subnet 9, Pre-Training. Participants would train local versions of their models on their data, with updates (parameters or gradients) getting aggregated and used to improve a global model.
Experiment setup
For our federated learning experiment, we had eight miners, all contributing to one global model. Each had a batch size of eight and communicated with each other every fifth batch.
To benchmark our results, we compared them to a single miner with a batch size of 8 as a lower bound, and a data parallelism setup with a batch size of 128 (8*16) as an upper bound. The single miner represents the current setup for subnet 9, where model pre-training occurs from one agent at a time. While multiple models are submitted to our competitions, each of them are trained by a single entity.
Data parallelism, on the other hand, represents a perfect linking between miners, as if they were all set on the same data center, being able to share unlimited amounts of information with no latency. The agents communicate frequently to synchronize updates, making for a tight and efficient setup. This is how centralized models can get trained, as the datasets and computational resources can be easily controlled across machines. This, coupled with the requirement for fast bandwidth makes it an impossibility in a decentralized setting. However, it shows what peak performance would look like.
For the experiment to be successful, it must beat the single miner, otherwise there’s no improvement. But we cannot expect it to beat data parallelism, because that is the most optimal of setups, where multiple participants are tightly aligned, communicating more often, and sharing more batches. We are hoping our federated learning system will perform close to this best-case scenario. Therefore, these two setups act as a way of adding context and framing our results.
For gradient transfer, a simple 10-fold topK compression was applied to achieve sufficiently fast communication (every fifth batch). In the future, this will likely be improved through either the application of Nous Research’s DeMo, or our own budgeted compression to achieve higher ratios.
Preliminary results
We conducted our federated learning experiment using GPT2, a smaller LLM with only 150M parameters.
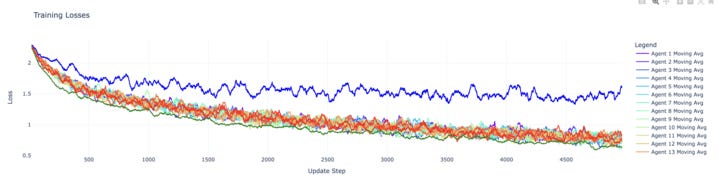
The blue line represents the single miner, the green line represents the data parallel learner, and the rest of the lines represent our eight agents powered by federated learning.
Here, the federated learners consistently beat the single miner, and even display nearly identical performance to the data parallel learner. This reveals federated learning is possible on subnet 9, and is worth further exploring. Even more impressive is that we generated SOTA performance compared to Google Deepmind’s DiLoCo (Distributed Low-Communication Training of Language Models) paper.
What to expect for subnet 9
Our experiment reveals that federated learning can be achieved on subnet 9 (which may also work on subnet 37, Fine-Tuning). While the test was conducted on smaller models, it gives a greenlight for us to continue.
Our initial investigations suggest that performance scales favorably on larger models, but further research is required to ensure our methodology can function smoothly on up to 100B+ models. Zooming out, our results indicate federated learning can flourish on Bittensor - enabling participants to contribute to building models in a distributed way, bringing more collaboration to our competitions and deeper decentralization to the ecosystem.