

Data determinant? Why we’re updating the datasets on SN9 to improve performance
LLMs are even more dependent on their dataset than first thought. To unlock performance, higher-quality datasets are essential - which is why we're enhancing Subnet 9's evaluation and training dataset


by Rodrigo LPA and Alan Aboudib.
We have already observed that improved resource allocation through Bittensor can significantly enhance model performance. Equally crucial is dataset quality that can have a profound impact on a model’s behaviour and performance. While pre-training, architecture, and incentives matter - and pose deep technical challenges of their own - data is the critical raw material upon which everything else depends.
LLM pre-training expert Non-Interactive argues in their recent post that despite hours of ‘tweaking various model configurations and parameters,’ increasing dataset convergence across different generative models leads to performance convergence. In other words, when ‘trained on the same dataset for long enough, pretty much every model with enough weights and training time converges to the same point.’
Although this downplays the pre-training of LLMs—challenges that Subnet 9 miners are all too familiar with—it usefully underscores the critical role of data, and the disproportionate role of dataset selection.
That’s why we’re expanding Subnet 9’s evaluation and training dataset. Shifting our evaluation process from Falcon's RefinedWeb to Huggingface's larger and higher-quality FineWeb dataset will undoubtedly improve model performance on SN9. The figure below shows a higher average performance of models trained on FineWeb compared to training on RefinedWeb. Please refer to FineWeb page for more information and performance metrics.
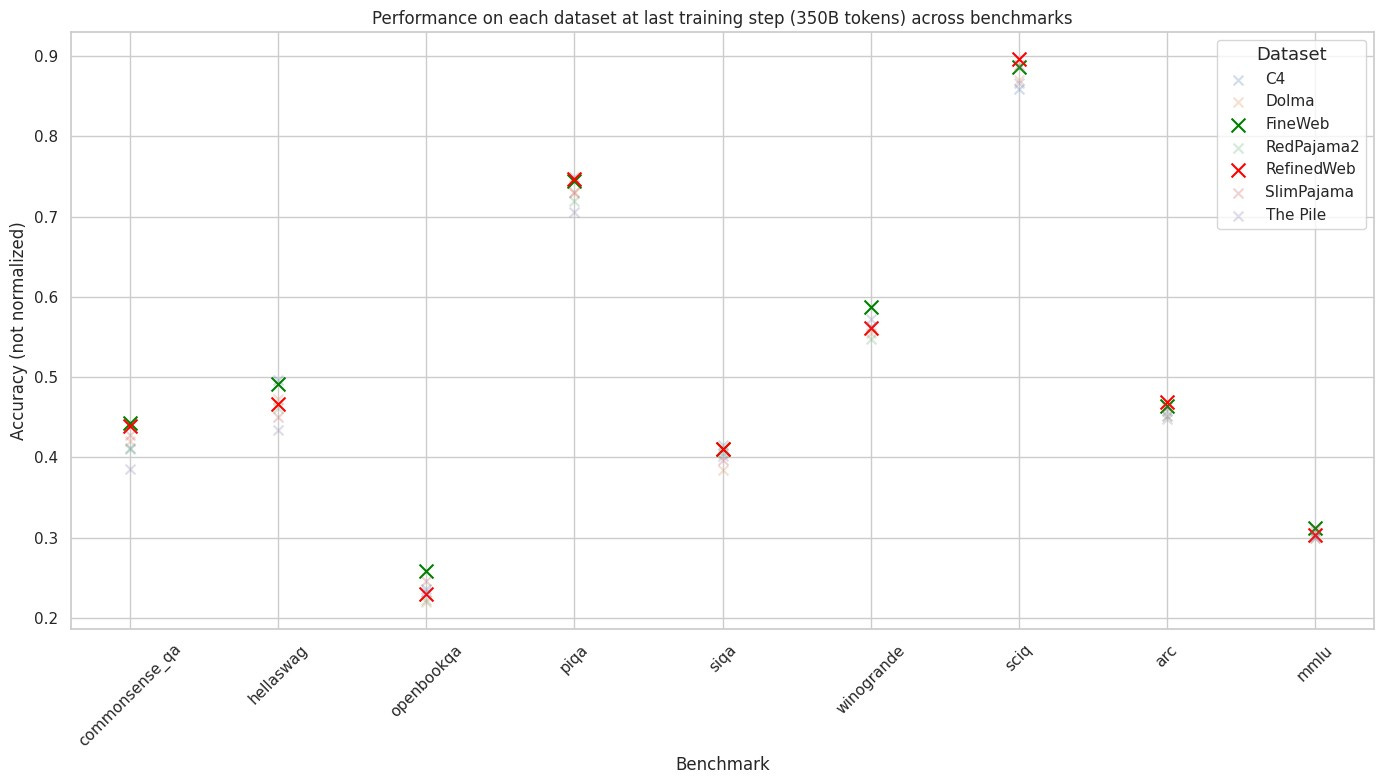
This is a step forward - made possible by our in-house R&D team and our wider community. Our decision was informed by the engaged, ongoing discussions and debates within our community, whose growing consensus that an upgrade was necessary convinced us that the time was right. As we migrate, we’ll continue to consult with SN9 stakeholders. We will deliver a detailed roadmap for this transition well in advance, supported by community announcements to provide clear updates and a space for exchanging ideas on implementing this important change.
In addition to incentivizing the best loss, we want to incentivize the steepest descent of the loss landscape. To achieve this goal, we are developing a more dynamic approach to adjusting the time-based epsilon hyperparameter. This will help our models avoid getting stuck in local minima for unnecessary durations, unlocking greater efficiency in resource use and training. Together with the migration to the FineWeb dataset, these enhancements will boost performance throughout SN9.
Amidst these changes, Subnet 9’s core commitment remains constant: innovating and improving performance to push the boundaries of what Bittensor and its community can achieve. By enhancing our dataset and refining our processes, we’re doubling down on delivering results.