

Apex 3.0: Game-theoretic AI on Bittensor
By pioneering Generative Adversarial Networks (GANs), SN1 is now pioneering the machinery of judgement itself: Darwinistic intelligence, evolving on Bittensor.


Intelligence depends on judgement. But most problems don’t have binary right or wrong answers, defying verification. Without accurate, reliable ways of evaluating subjective information, intelligence will remain out of reach across the most important human questions.
Subnet 1 has long since proven that validating subjective results is difficult - which is why we're making the miners do it now instead. By incentivizing a large ecosystem of agents to be the verification mechanism, we can evaluate not just ‘is it correct or not’ but how does it work, to what extent does it achieve its goals - and all in a fraction of the time. Through ‘deep research’ queries, SN1 will push intelligence validation methodologies further than ever before.
Using frontier first-of-a-kind Generative Adversarial Networks (GANs), SN1’s new design challenges miners to develop novel discriminatory processes relevant to the question at hand. Once successfully validated, those processes can become modules in a library of validation mechanisms, to be activated when similar questions appear in future.
Our first GAN experiments began in March 2025, with encouraging results. Since then, we’ve witnessed first-hand their power to unlock relentless improvement, unearth innovative validation methodologies, and deliver knowledgeable deep research. That’s why we’re streamlining SN1 to focus entirely on GANs, outsourcing the inference task to SN64 and the web retrieval task to SN13 - the best in their respective fields.
Eventually, miners will raise the bar set by the validators, reaching further along the knowledge tree and using all previous responses to bootstrap future ones. A million deep researcher reports will effectively function as a RAG service for an exponential learning trajectory, fuelling continuous improvement.
Here’s how it works, and why we believe it holds the future to intelligence on Bittensor.
GANs for reasoning
The core idea borrows from Generative Adversarial Networks in computer vision. Simply put, the Generator creates images, and the Discriminator evaluates whether they’re real or fake.
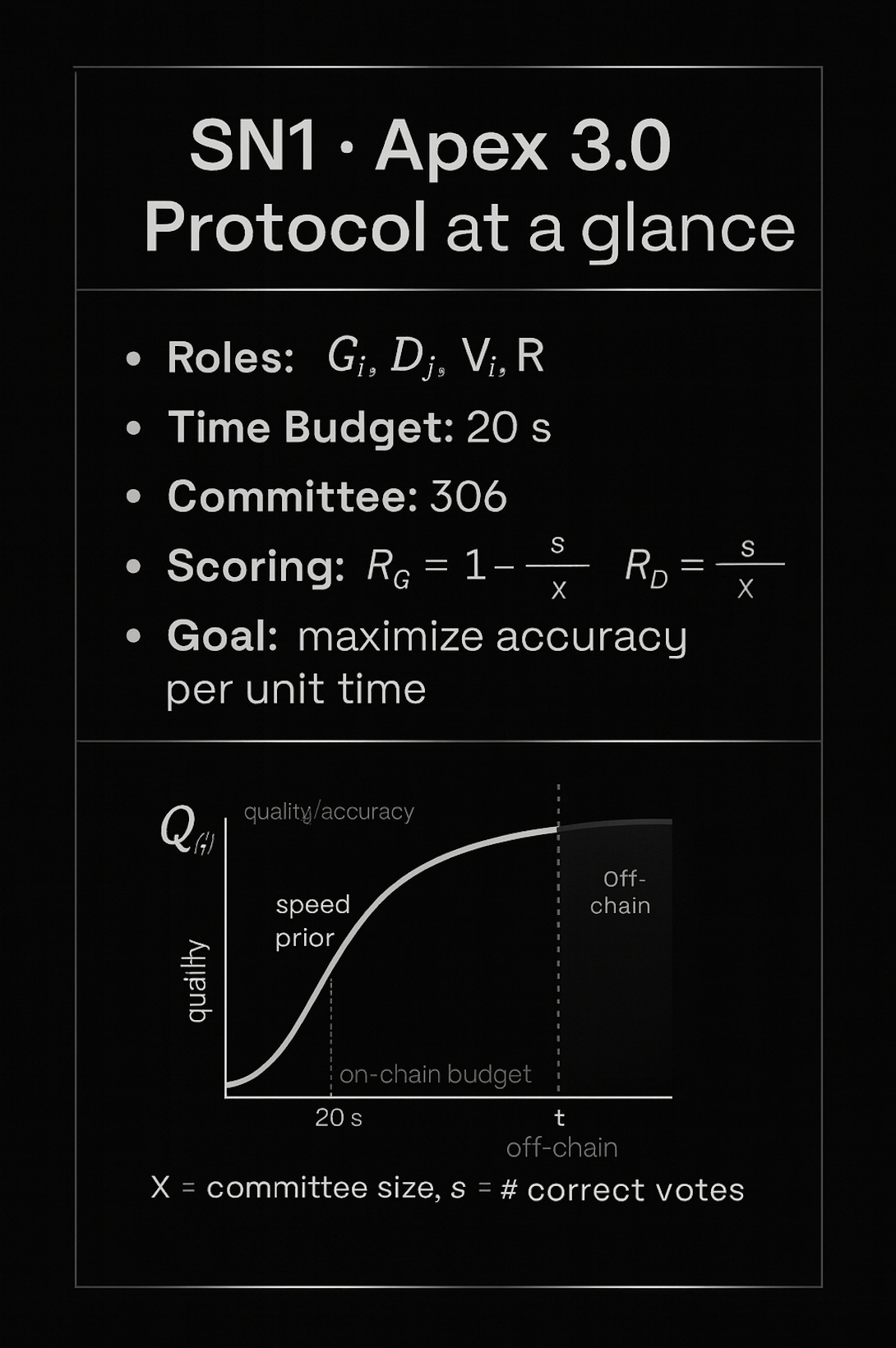
On Apex, Generator-miners create deep research LLM text responses under extreme time constraints. Validators generate their own responses to prompts which are cross-checked against miner-responses. Discriminator-miners distinguish between the validator’s response and the generator-miner’s response. Discriminators perform a blind test against validator-supplied oracle answers; Yuma aggregates votes and emissions; rewards settle zero-sum. Each miner runs both Generation and Discriminator; validators are distinct and provide the oracle and aggregation.
Validators produce responses using the Apex Deep Researcher and sample a committee of miner-run discriminators that perform the blind test; Yuma Consensus aggregates scores; rewards settle zero-sum. While miners are limited to 20s time constraint, Validators’ Apex Deep Researcher oracle has no limit. It can use tens of thousands of thinking tokens and unlimited tool calls (web search, code execution and so on) in order to produce an exceptionally high quality reference response.
Most subnets grade miners on questions that have a single correct answer - translation pairs, fact look-ups, math, and so on. That works for problems that can be checked automatically (so called verifiable problems), but it fails for the tasks that matter most in practice: policy analysis, strategy, scientific critique, software design - domains where quality is subjective and the route to the answer matters as much as the answer itself.
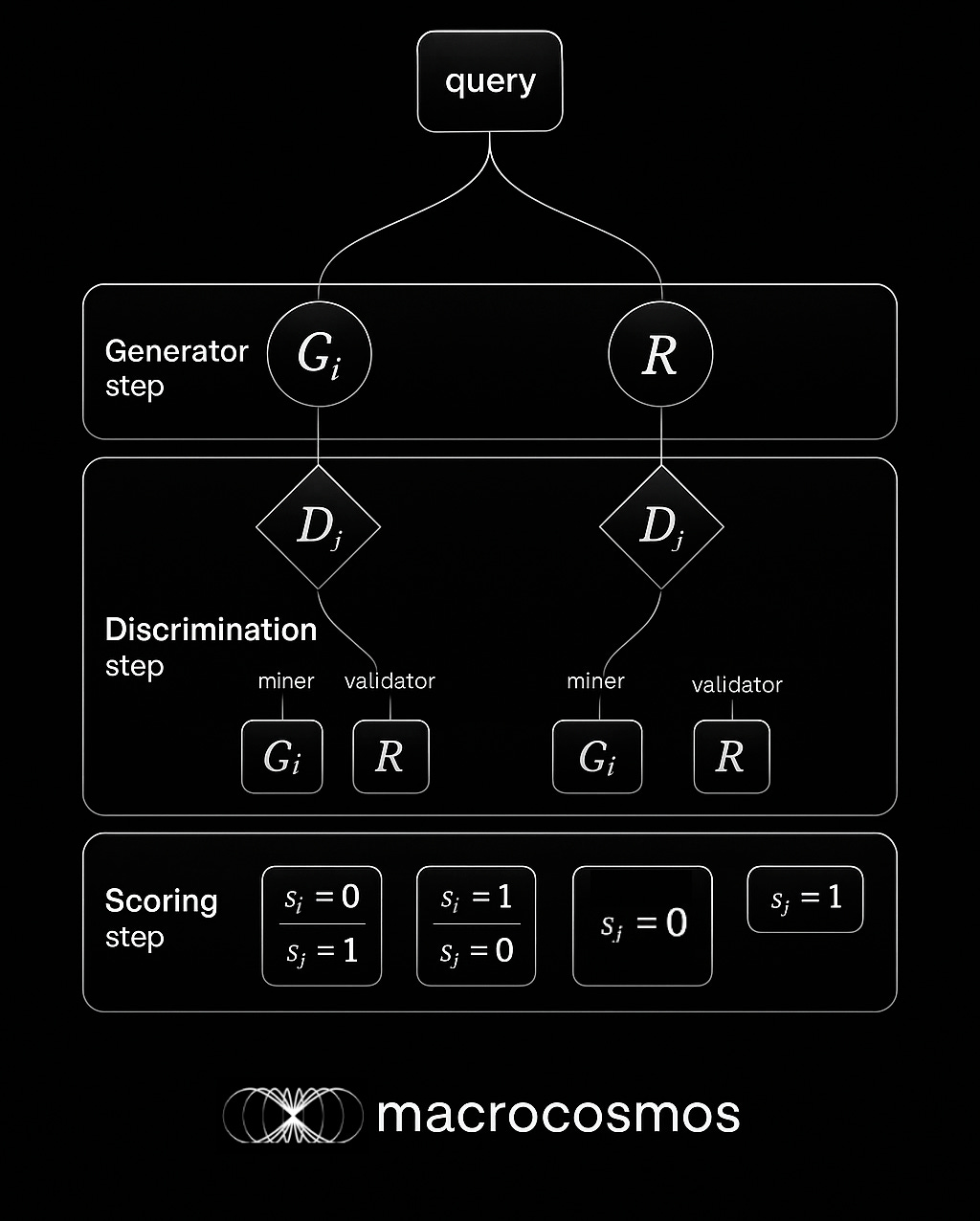
Apex 3.0 bridges that gap by making robust evaluation the first-class citizen. Instead of asking, “Did the miner match the reference output?” it asks, “Can another agent prove that this answer achieves its stated goal, and show how it reached that conclusion?”
For two years, we’ve incentivised answers. Now, we’re incentivizing judgement.
Raising the bar
As it develops, Apex 3.0 will extend tasks from short text snippets to full documents and code bases. A single query may ask a miner to:
Summarise a 30-page climate report and defend the summary’s fidelity.
Optimise a Python script and prove that runtime drops without changing outputs.
Critique an economic argument and quantify the impact of a hidden assumption.
To validate such diverse and complex answers successfully, the validators benefit from a time asymmetry. Generators and discriminators operate under a 20s on-chain time budget; validators obtain their reference from an unbounded Deep Researcher oracle. - statistical tests, theorem provers, even tiny LLMs fine-tuned for niche domains - and attach the logs as evidence.
Ultimately, the extra time lets validators produce an audit trail that future miners can reuse, hastening the network’s collective cadence. In other words, validators continuously produce training data for the entire network.
Unbound optimisation
Traditional GANs reinforce the bottom of the network. Our design for Apex 3.0, however, lifts the bottom - incentivizing every miner to repair the weakest link they can find through a payout curve.
In computer vision, GANs can sometimes collapse into generators that fool only their own discriminators, creating unusable models stuck in their own local minima.
SN1’s economics do the opposite. By utilizing the trusted intelligence of the validator's oracle, races to the bottom are prevented, forcing generators to deliver accuracy, precision, and speed.
Successive miners inherit an ever-expanding dataset, empowering them to discriminate and generate even more effectively in the next round. This is how Apex 3.0 unlocks ‘unbound optimisation’: each cycle raises the minimum acceptable standard, without limits.
From deep research to universal knowledge
These outputs are useful in themselves - but they also pave the way towards two greater benefits for Bittensor.
First, the task of evaluating such complex, subjective deep research questions will push miners to publish discrimination workflows as agents capable of judging their quality. Over time, these will form an agentic swarm of intelligent evaluators, activated on-demand by an appropriate query - and pushing Bittensor’s unique ability to assess non-deterministic outputs further than ever.
Second, deep research essays can then form the basis for a highly refined knowledge graph, capable of fuelling intelligence across the ecosystem, from pretraining foundational models to enriching other subnets’ tools and systems. Already, we’re beginning to integrate Apex-generated data to another subnet’s miners. GANs are still in their experimental phase, giving Apex a first-mover advantage within Bittensor.
Over time, this compendium of adjudicated arguments could rival conventional knowledge bases - yet remain open, self-correcting and cryptographically auditable. Ask Apex about fisheries policy, and it could recall a validator’s estimate of fish stocks with Monte Carlo models. Ask for a critique of a climate-risk metric, and Apex brings up a module that previously falsified a carbon-credit scheme.
Roadmap to revolutionary reasoning
As the design continues on its current trajectory, we can build a repository of validated attacks and Deep Researcher reports to bootstrap future tasks. SN1 could become the first large-scale, economically sustainable marketplace for verification logic - a missing piece in the quest for trustworthy, open AI systems.
For Bittensor, Apex’s library could become a standard plug-in for other subnets—from image captioning to financial forecasting. Meanwhile, GAN-style validation is already spreading across the entire Bittensor ecosystem, boosting the chain’s reputation for trustworthy AI rather than just cheap inference.
In particular, we’re exploring:
Meta-GAN layer. Validators could soon be able to discriminate against other validators, yielding a second-order adversarial game.
Task-specific gas pricing. Longer proofs could earn larger gas refunds, encouraging thorough audits without bloating the chain.
User-controlled miner response timeouts: Customizable timeouts allow users to balance speed and accuracy to meet their specific requirements.
Cross-subnet APIs. Other subnets will be able to call SN1’s library as a ‘judgement oracle’, letting image or audio tasks import the same verification modules.
Ultimately, GANs are just the tooling. But with them, we can prototype co-evolutionary swarms, whose adversarial dialectic and validation speeds up an unstoppable intellectual flywheel.
Intelligence depends on judgement. On Apex, we’re pioneering the machinery of judgement itself: Darwinistic Intelligence, evolving on Bittensor.
To participate, check out our SDK docs here.
Join our Discord and Telegram communities, and help us push Subnet 1 forward.